N13-Bonus_Unit_3-Advanced_Topics_in_Reinforcement_Learning-F5-Language_models_in_RL
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit3/from-q-to-dqn?fw=pt
Language models in RL
RL中的语言模型
LMs encode useful knowledge for agents
LMS为代理编码有用知识
Language models (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to encode various knowledge including abstract ones about the physical rules of our world (for instance what is possible to do with an object, what happens when one rotates an object…).
语言模型(LMS)在处理文本时可以显示出令人印象深刻的能力,例如问题回答,甚至是逐步推理。此外,他们在海量文本语料库上的培训使他们能够编码各种知识,包括关于我们世界的物理规则的抽象知识(例如,可以对对象做什么,当一个对象旋转…时会发生什么)。
A natural question recently studied was could such knowledge benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked of any learning method. This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.
最近研究的一个自然问题是,当试图解决日常任务时,这种知识是否会让机器人等代理受益。虽然这些工作显示了有趣的结果,但所提出的代理缺乏任何学习方法。这一限制阻止了这些代理适应环境(例如,修复错误的知识)或学习新技能。
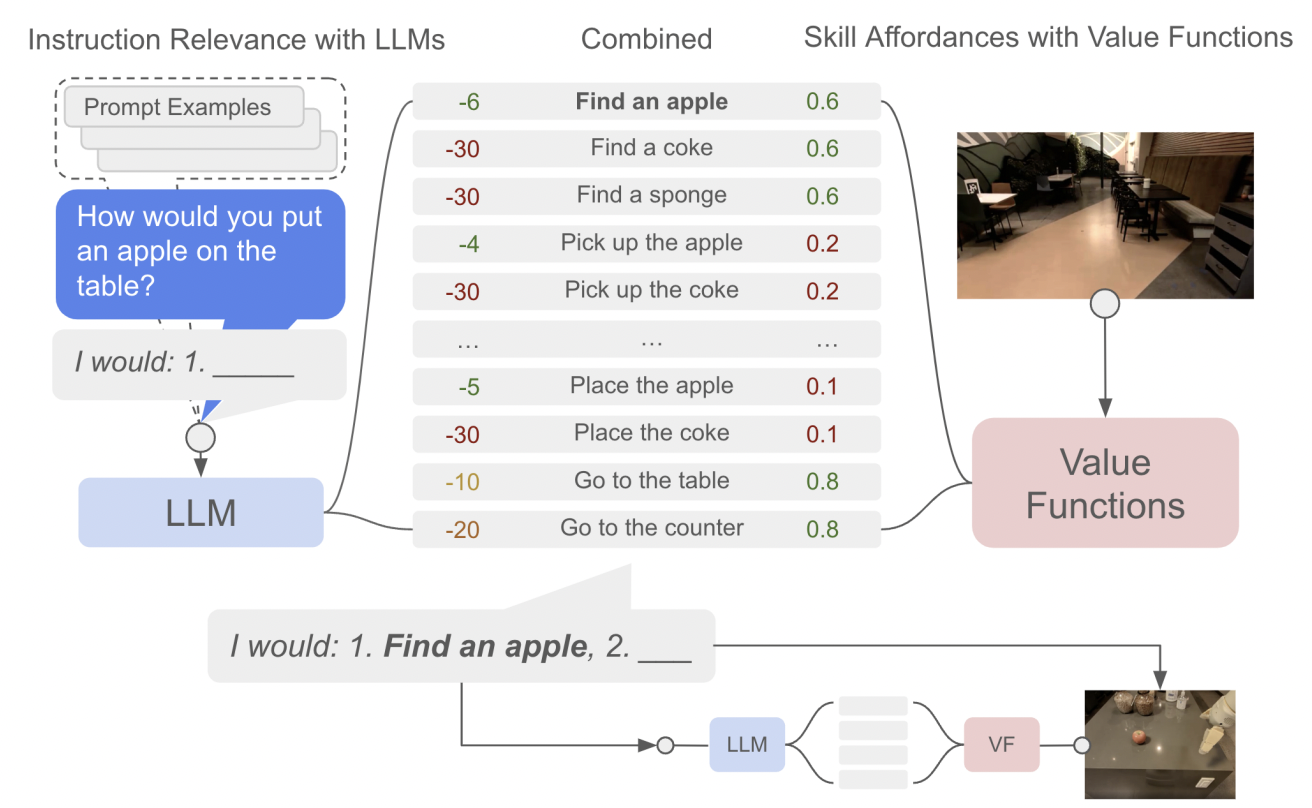
Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
语言来源:通向乐于助人的机器人:机器人非洲舞中的扎根语言
LMs and RL
LMS和RL
There is therefore a potential synergy between LMs which can bring knowledge about the world, and RL which can align and correct these knowledge by interacting with an environment. It is especially interesting from a RL point-of-view as the RL field mostly relies on the Tabula-rasa setup where everything is learned from scratch by agent leading to:
因此,LMS和RL之间存在潜在的协同作用,前者可以带来关于世界的知识,后者可以通过与环境互动来调整和纠正这些知识。从RL的角度来看,这特别有趣,因为RL场主要依赖于Tabula-Rasa设置,其中代理从头开始学习所有东西,从而:
Sample inefficiency
样本效率低下
Unexpected behaviors from humans’ eyes
来自人类眼睛的意外行为
As a first attempt, the paper “Grounding Large Language Models with Online Reinforcement Learning” tackled the problem of adapting or aligning a LM to a textual environment using PPO. They showed that the knowledge encoded in the LM lead to a fast adaptation to the environment (opening avenue for sample efficiency RL agents) but also that such knowledge allowed the LM to better generalize to new tasks once aligned.
作为第一次尝试,《用在线强化学习使大型语言模型扎根》一文解决了使用PPO将LM适应或对齐到文本环境的问题。他们表明,在LM中编码的知识导致对环境的快速适应(为样本效率RL试剂打开了道路),但这种知识也允许LM在匹配后更好地概括到新的任务。
Another direction studied in “Guiding Pretraining in Reinforcement Learning with Large Language Models” was to keep the LM frozen but leverage its knowledge to guide an RL agent’s exploration. Such method allows the RL agent to be guided towards human-meaningful and plausibly useful behaviors without requiring a human in the loop during training.
在“用大型语言模型指导强化学习中的预训练”中研究的另一个方向是保持LM冻结,但利用其知识来指导RL代理的探索。这种方法允许RL代理被引导到对人类有意义和看似有用的行为,而不需要在训练期间有人参与。
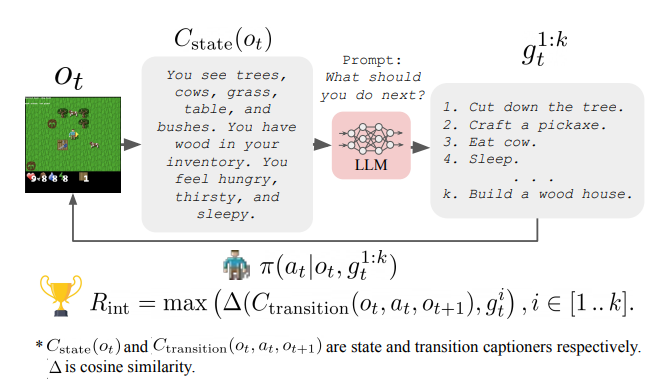
Source: Towards Helpful Robots: Grounding Language in Robotic Affordances
Several limitations make these works still very preliminary such as the need to convert the agent’s observation to text before giving it to a LM as well as the compute cost of interacting with very large LMs.
语言来源:走向有帮助的机器人:机器人Affordance中的接地语言几个限制使这些工作仍然非常初步,例如在将代理的观察结果提供给LM之前需要将其转换为文本,以及与非常大的LMS交互的计算成本。
Further reading
进一步阅读
For more information we recommend you check out the following resources:
有关更多信息,我们建议您查看以下资源:
- Google Research, 2022 & beyond: Robotics
- Pre-Trained Language Models for Interactive Decision-Making
- Grounding Large Language Models with Online Reinforcement Learning
- Guiding Pretraining in Reinforcement Learning with Large Language Models
Author
谷歌研究,2022年及以后:机器人用于交互决策的预训练语言模型通过在线强化学习获取大型语言模型使用大型语言模型指导强化学习的预培训作者
This section was written by Clément Romac
本部分由Clément Romac撰写