N13-Bonus_Unit_3-Advanced_Topics_in_Reinforcement_Learning-C2-Online_Reinforcement_Learning
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit2/conclusion?fw=pt
Offline vs. Online Reinforcement Learning
离线强化学习与在线强化学习
Deep Reinforcement Learning (RL) is a framework to build decision-making agents. These agents aim to learn optimal behavior (policy) by interacting with the environment through trial and error and receiving rewards as unique feedback.
深度强化学习(RL)是一个构建决策主体的框架。这些代理的目标是通过试错与环境互动,并接受作为唯一反馈的奖励,从而学习最佳行为(策略)。
The agent’s goal is to maximize its cumulative reward, called return. Because RL is based on the reward hypothesis: all goals can be described as the maximization of the expected cumulative reward.
代理人的目标是最大化其累积回报,称为回报。因为RL是基于报酬假设的:所有的目标都可以用期望累积报酬的最大化来描述。
Deep Reinforcement Learning agents learn with batches of experience. The question is, how do they collect it?:
深度强化学习代理通过批量经验学习。问题是,他们如何收集这些信息?
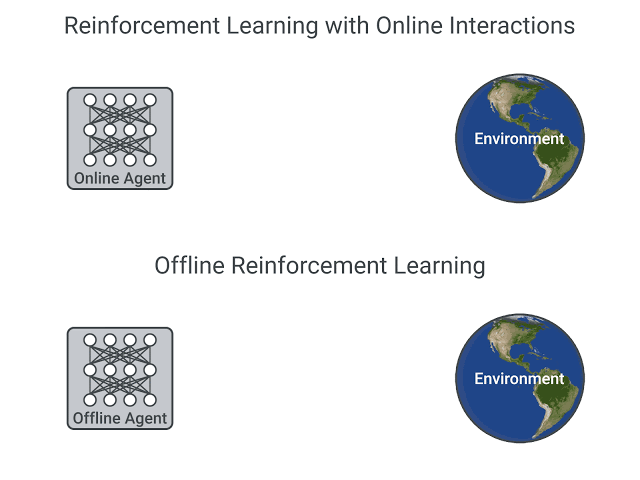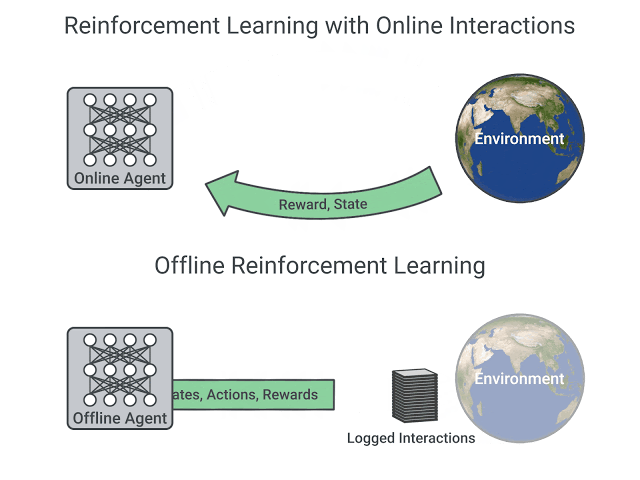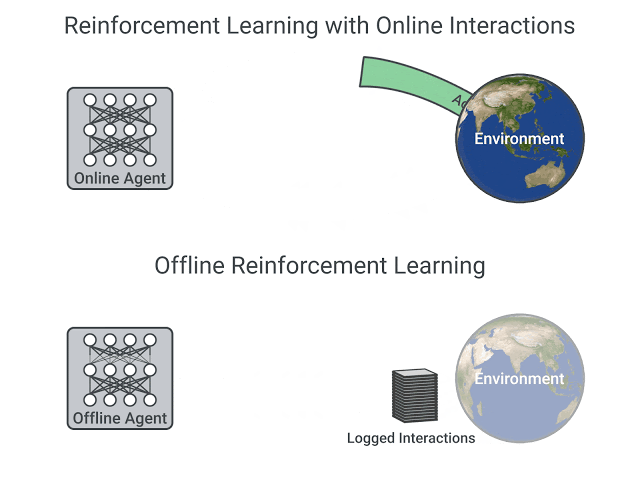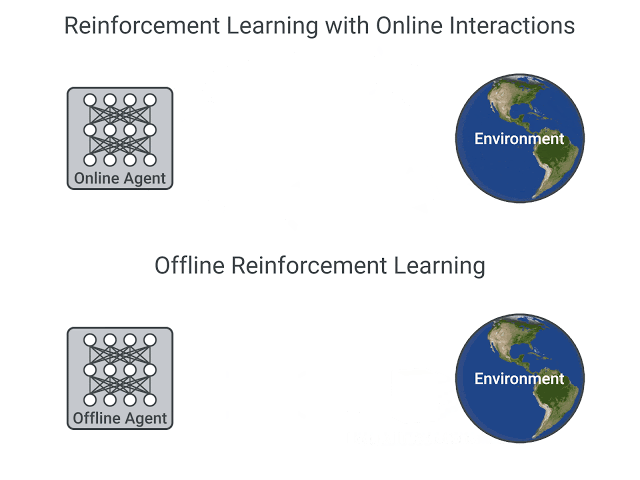
A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from this post
单元奖金3缩略图在线和离线环境下强化学习的比较,图来自本文
- In online reinforcement learning, which is what we’ve learned during this course, the agent gathers data directly: it collects a batch of experience by interacting with the environment. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
But this implies that either you train your agent directly in the real world or have a simulator. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure (if the simulator has flaws that may provide a competitive advantage, the agent will exploit them).
在在线强化学习中,这是我们在本课程中学到的,代理直接收集数据:它通过与环境交互来收集一批经验。然后,它立即使用这一经验(或通过一些重放缓冲区)来从中学习(更新其策略)。但这意味着您要么直接在现实世界中培训您的代理,要么有一个模拟器。如果没有,您需要构建它,这可能非常复杂(如何在环境中反映真实世界的复杂现实?)、昂贵和不安全(如果模拟器有可能提供竞争优势的缺陷,代理将利用它们)。
- On the other hand, in offline reinforcement learning, the agent only uses data collected from other agents or human demonstrations. It does not interact with the environment.
The process is as follows:
另一方面,在离线强化学习中,智能体只使用从其他智能体或人类演示中收集的数据。它不与环境相互作用。过程如下:
- Create a dataset using one or more policies and/or human interactions.
- Run offline RL on this dataset to learn a policy
This method has one drawback: the counterfactual queries problem. What do we do if our agent decides to do something for which we don’t have the data? For instance, turning right on an intersection but we don’t have this trajectory.
使用一个或多个策略和/或人工交互创建数据集。对此数据集运行脱机RL以了解策略此方法有一个缺点:反事实查询问题。如果我们的代理决定做一些我们没有数据的事情,我们该怎么办?例如,在十字路口右转,但我们没有这个轨迹。
There exist some solutions on this topic, but if you want to know more about offline reinforcement learning, you can watch this video
关于这个话题有一些解决方案,但如果你想了解更多关于离线强化学习的知识,你可以观看这个视频
Further reading
进一步阅读
For more information, we recommend you check out the following resources:
有关更多信息,我们建议您查看以下资源:
- Offline Reinforcement Learning, Talk by Sergei Levine
- Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Author
脱机强化学习,谢尔盖·莱文的演讲脱机强化学习:教程、回顾和对开放问题的看法作者
This section was written by Thomas Simonini
本部分由托马斯·西莫尼尼撰写