K10-Unit_7-Introduction_to_Multi_Agents_and_AI_vs_AI-C2-Designing_Multi_Agents_systems
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unitbonus1/train?fw=pt
Designing Multi-Agents systems
设计多智能体系统
For this section, you’re going to watch this excellent introduction to multi-agents made by Brian Douglas .
在这一部分中,您将观看由Brian Douglas所做的关于多代理的精彩介绍。
In this video, Brian talked about how to design multi-agent systems. He specifically took a vacuum cleaner multi-agents setting and asked how they can cooperate with each other?
在这段视频中,布莱恩谈到了如何设计多代理系统。他专门拿了一个吸尘器多代理设置,询问他们如何相互合作?
We have two solutions to design this multi-agent reinforcement learning system (MARL).
我们有两种解决方案来设计这个多智能体强化学习系统(MAIL)。
Decentralized system
分散式系统
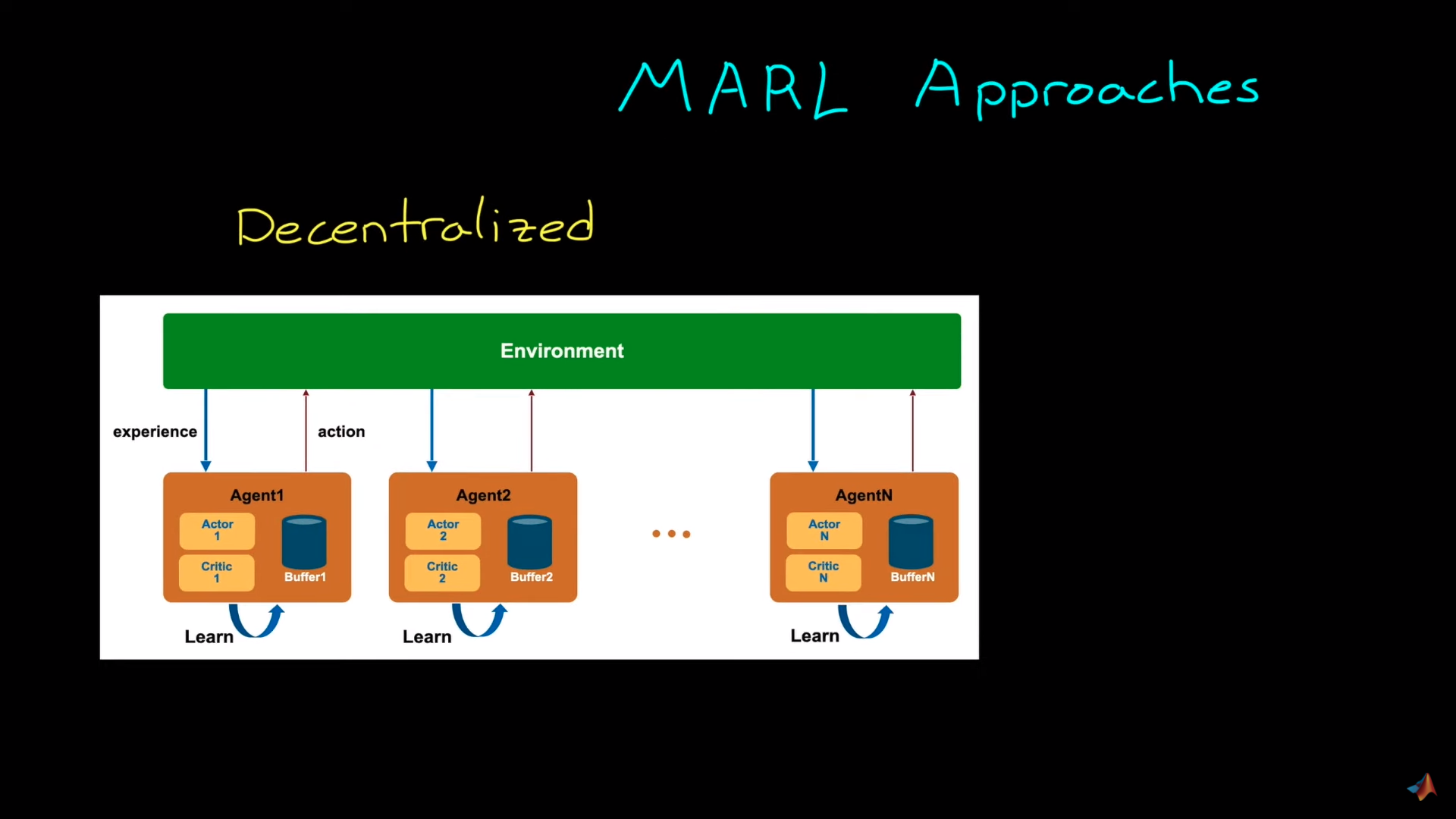
Source: Introduction to Multi-Agent Reinforcement Learning
In decentralized learning, each agent is trained independently from others. In the example given, each vacuum learns to clean as many places as it can without caring about what other vacuums (agents) are doing.
分散式来源:多智能体强化学习简介在分散式学习中,每个智能体都是独立于其他智能体进行训练的。在给出的例子中,每个吸尘器学习尽可能多地清洁,而不关心其他吸尘器(代理)正在做什么。
The benefit is that since no information is shared between agents, these vacuums can be designed and trained like we train single agents.
其好处是,由于代理之间不共享信息,这些真空可以像我们培训单个代理一样进行设计和训练。
The idea here is that our training agent will consider other agents as part of the environment dynamics. Not as agents.
这里的想法是,我们的培训代理将考虑其他代理作为环境动态的一部分。不是以特工的身份。
However, the big drawback of this technique is that it will make the environment non-stationary since the underlying Markov decision process changes over time as other agents are also interacting in the environment.
And this is problematic for many Reinforcement Learning algorithms that can’t reach a global optimum with a non-stationary environment.
然而,这种技术的最大缺点是它将使环境是非平稳的,因为底层的马尔可夫决策过程随着时间的推移而变化,因为环境中的其他主体也在相互作用。这对于许多在非平稳环境下不能达到全局最优的强化学习算法来说是有问题的。
Centralized approach
集中化方法
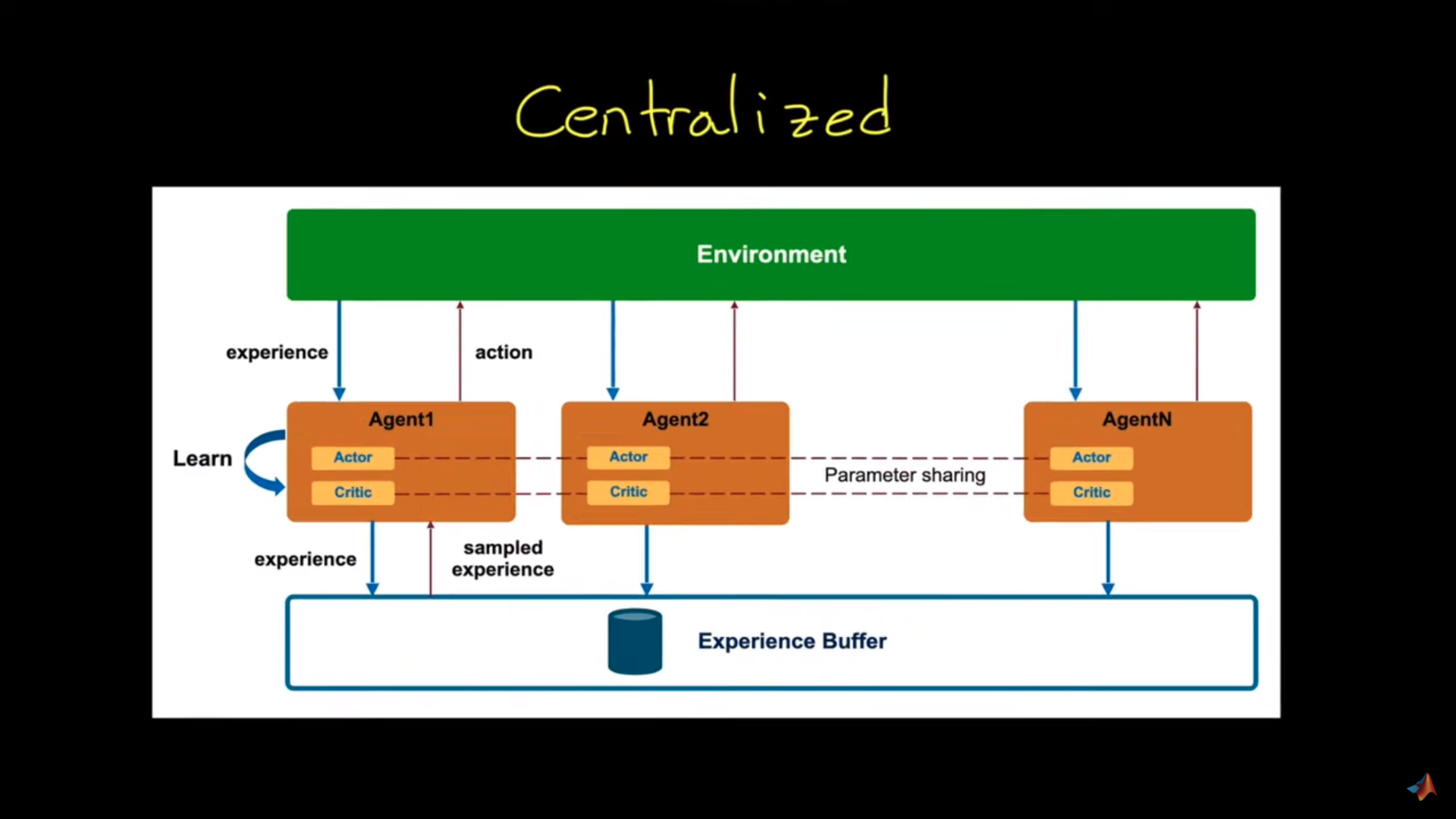
Source: Introduction to Multi-Agent Reinforcement Learning
In this architecture, we have a high-level process that collects agents’ experiences: experience buffer. And we’ll use these experiences to learn a common policy.
集中式来源:多智能体强化学习简介在这个体系结构中,我们有一个收集智能体经验的高级过程:经验缓冲区。我们将利用这些经验来学习共同的政策。
For instance, in the vacuum cleaner, the observation will be:
例如,在吸尘器中,观察将是:
- The coverage map of the vacuums.
- The position of all the vacuums.
We use that collective experience to train a policy that will move all three robots in the most beneficial way as a whole. So each robot is learning from the common experience.
And we have a stationary environment since all the agents are treated as a larger entity, and they know the change of other agents’ policies (since it’s the same as theirs).
吸尘器的覆盖范围图。所有吸尘器的位置。我们利用这些集体经验来训练一项政策,将以最有利的方式整体移动所有三个机器人。因此,每个机器人都在从共同的经验中学习。我们有一个固定的环境,因为所有的代理都被视为一个更大的实体,并且他们知道其他代理的策略的变化(因为这与他们的相同)。
If we recap:
如果我们回顾一下:
In decentralized approach, we treat all agents independently without considering the existence of the other agents.
在去中心化方法中,我们独立地对待所有的代理,而不考虑其他代理的存在。
- In this case, all agents consider others agents as part of the environment.
- It’s a non-stationarity environment condition, so non-guaranty of convergence.
In centralized approach:
在这种情况下,所有智能体都将其他智能体视为环境的一部分。这是一个非平稳的环境条件,因此不能保证收敛。在集中式方法中:
- A single policy is learned from all the agents.
- Takes as input the present state of an environment and the policy output joint actions.
- The reward is global.