I8-Unit_5-Introduction_to_Unity_ML_Agents-C2-The_SnowballTarget_environment
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unitbonus3/introduction?fw=pt
The SnowballTarget Environment
雪球目标环境

SnowballTarget is an environment we created at Hugging Face using assets from Kay Lousberg. We have an optional section at the end of this Unit if you want to learn to use Unity and create your environments.
雪球目标雪球目标是我们在Hugging Face时使用凯·卢斯伯格的资源创建的环境。如果你想学习使用Unity并创建你的环境,我们在本单元的末尾有一个可选的部分。
The agent’s Goal
代理人的目标
The first agent you’re going to train is called Julien the bear 🐻. Julien is trained to hit targets with snowballs.
你要训练的第一个特工叫熊🐻朱利安。朱利安接受过用雪球击中目标的训练。
The Goal in this environment is that Julien hits as many targets as possible in the limited time (1000 timesteps). It will need to place itself correctly from the target and shootto do that.
在这种环境下的目标是朱利安在有限的时间(1000个时间步)内击中尽可能多的目标。要做到这一点,它需要正确地将自己放置在目标位置并进行射击。
In addition, to avoid “snowball spamming” (aka shooting a snowball every timestep), Julien has a “cool off” system (it needs to wait 0.5 seconds after a shoot to be able to shoot again).
此外,为了避免“雪球垃圾”(又名每一个时间步打一个雪球),朱利安还有一个“冷却”系统(它需要在拍摄后等待0.5秒才能再次拍摄)。

The agent needs to wait 0.5s before being able to shoot a snowball again
冷却系统代理需要等待0.5秒才能再次射击雪球
The reward function and the reward engineering problem
报酬函数与报酬工程问题
The reward function is simple. The environment gives a +1 reward every time the agent’s snowball hits a target. Because the agent’s Goal is to maximize the expected cumulative reward, it will try to hit as many targets as possible.
奖励功能很简单。每次代理的雪球击中目标时,环境都会给予+1奖励。因为代理的目标是最大化预期的累积回报,所以它会尝试击中尽可能多的目标。

We could have a more complex reward function (with a penalty to push the agent to go faster, for example). But when you design an environment, you need to avoid the reward engineering problem, which is having a too complex reward function to force your agent to behave as you want it to do.
Why? Because by doing that, you might miss interesting strategies that the agent will find with a simpler reward function.
奖励系统我们可以有一个更复杂的奖励功能(例如,通过惩罚来推动代理人走得更快)。但在设计环境时,您需要避免奖励工程问题,即奖励函数太复杂,无法迫使您的代理按您希望的方式行事。为什么?因为这样做,你可能会错过有趣的策略,而代理商会用更简单的奖励函数找到这些策略。
In terms of code, it looks like this:
在代码方面,它看起来像这样:

赏金
The observation space
观察空间
Regarding observations, we don’t use normal vision (frame), but we use raycasts.
对于观察,我们不使用正常视觉(帧),但我们使用光线投射。
Think of raycasts as lasers that will detect if they pass through an object.
可以将光线投射视为激光,它将检测光线是否穿过对象。
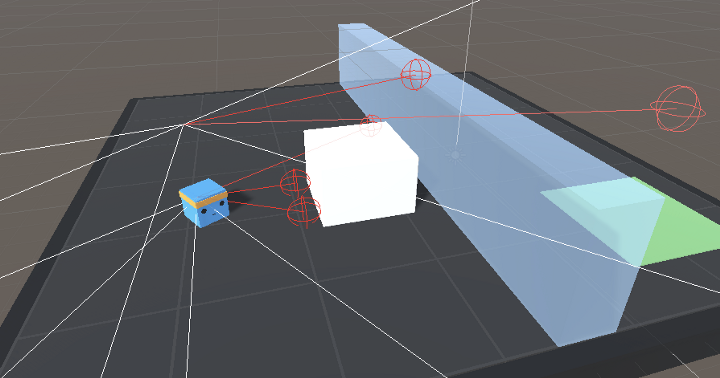
Source: ML-Agents documentation
In this environment, our agent has multiple set of raycasts:
光线投射来源:ML-Agents文档在此环境中,我们的代理具有多组光线投射:
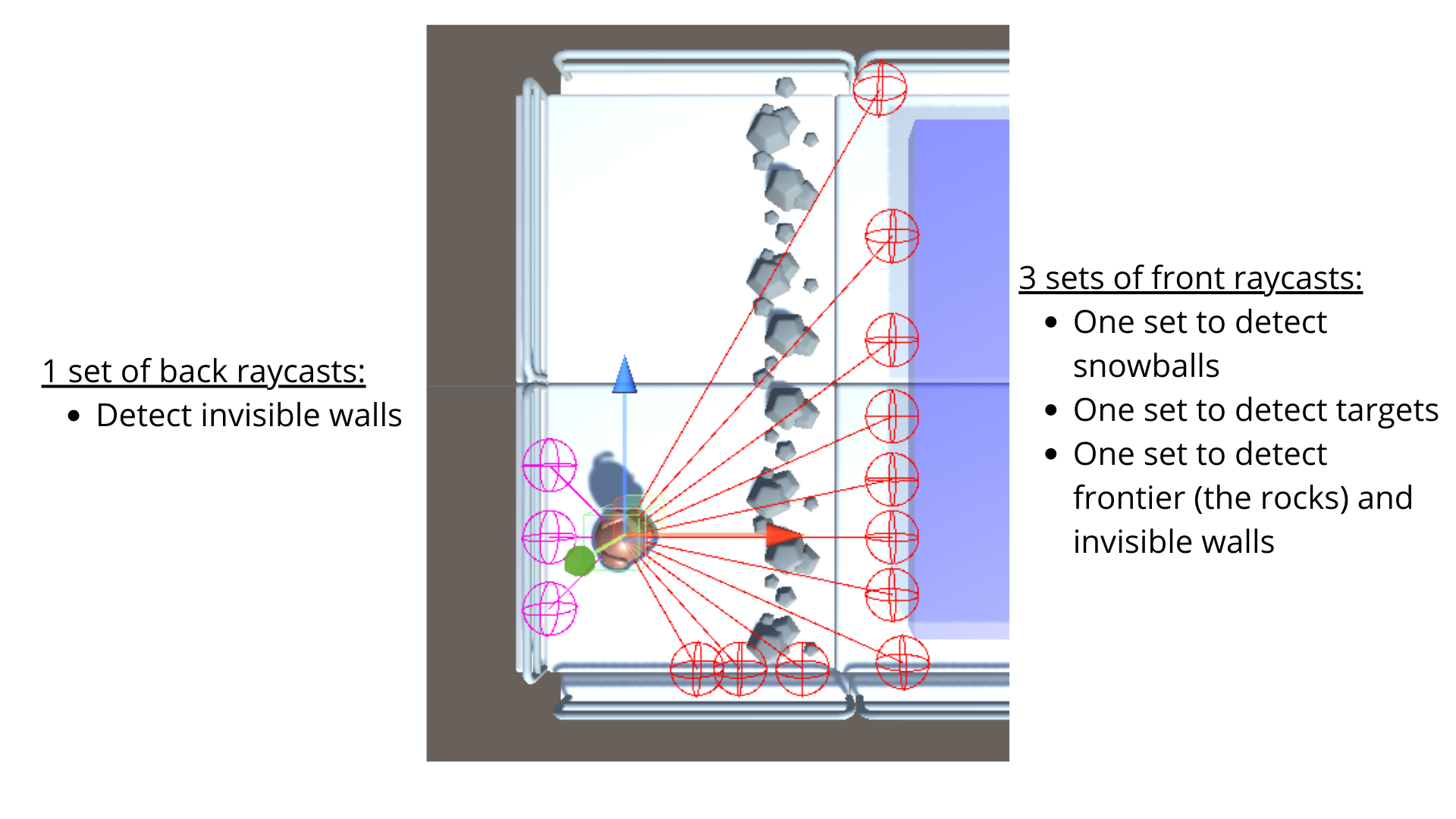
In addition to raycasts, the agent gets a “can I shoot” bool as observation.
光线投射除了光线投射之外,代理还会得到一个“我可以拍摄”布尔语作为观察。

OBS
The action space
动作空间
The action space is discrete:
动作空间是离散的:

动作空间