I8-Unit_5-Introduction_to_Unity_ML_Agents-B1-How_ML_Agents_works
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit8/conclusion-sf?fw=pt
How do Unity ML-Agents work?
Unity ML-Agents是如何工作的?
Before training our agent, we need to understand what ML-Agents is and how it works.
在培训我们的代理之前,我们需要了解ML-Agents是什么以及它是如何工作的。
What is Unity ML-Agents?
什么是Unity ML-Agents?
Unity ML-Agents is a toolkit for the game engine Unity that allows us to create environments using Unity or use pre-made environments to train our agents.
Unity ML-Agents是游戏引擎Unity的一个工具包,它允许我们使用Unity创建环境或使用预先建立的环境来培训我们的代理。
It’s developed by Unity Technologies, the developers of Unity, one of the most famous Game Engines used by the creators of Firewatch, Cuphead, and Cities: Skylines.
它是由联合技术公司开发的,联合技术公司是联合技术公司的开发商,联合技术公司是FireWatch、Cuphead和城市:天际线的开发者使用的最著名的游戏引擎之一。

Firewatch was made with Unity
FireWatch FireWatch是由Unity制造的
The six components
六个组成部分
With Unity ML-Agents, you have six essential components:
使用Unity ML-Agents,您有六个基本组件:
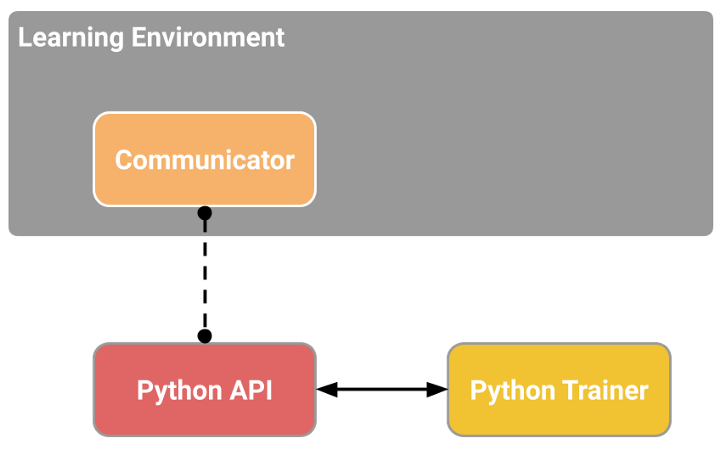
Source: Unity ML-Agents Documentation
MLAgents来源:Unity ML-代理文档
- The first is the Learning Environment, which contains the Unity scene (the environment) and the environment elements (game characters).
- The second is the Python Low-level API, which contains the low-level Python interface for interacting and manipulating the environment. It’s the API we use to launch the training.
- Then, we have the External Communicator that connects the Learning Environment (made with C#) with the low level Python API (Python).
- The Python trainers: the Reinforcement algorithms made with PyTorch (PPO, SAC…).
- The Gym wrapper: to encapsulate RL environment in a gym wrapper.
- The PettingZoo wrapper: PettingZoo is the multi-agents of gym wrapper.
Inside the Learning Component
第一个是学习环境,它包含Unity场景(环境)和环境元素(游戏角色)。第二个是Python低级API,它包含用于交互和操作环境的低级Python接口。它是我们用来启动培训的API。然后,我们有外部通信器,它连接学习环境(用C#制作)和低级的PythonAPI(PythonAPI)。健身房包装器:将RL环境封装在健身房包装器中。PettingZoo包装器:PettingZoo是健身房包装器的多代理。在学习组件中
Inside the Learning Component, we have three important elements:
在学习组件中,我们有三个重要元素:
- The first is the agent component, the actor of the scene. We’ll train the agent by optimizing its policy (which will tell us what action to take in each state). The policy is called Brain.
- Finally, there is the Academy. This component orchestrates agents and their decision-making processes. Think of this Academy as a teacher who handles Python API requests.
To better understand its role, let’s remember the RL process. This can be modeled as a loop that works like this:
第一个是代理组件,即场景的演员。我们将通过优化代理的策略来培训代理(这将告诉我们在每个州采取什么操作)。这项政策被称为大脑。最后,还有学院。该组件协调代理及其决策过程。将这个学院看作是一个处理Python API请求的教师。为了更好地理解它的角色,让我们记住RL过程。可以将其建模为工作原理如下的循环:
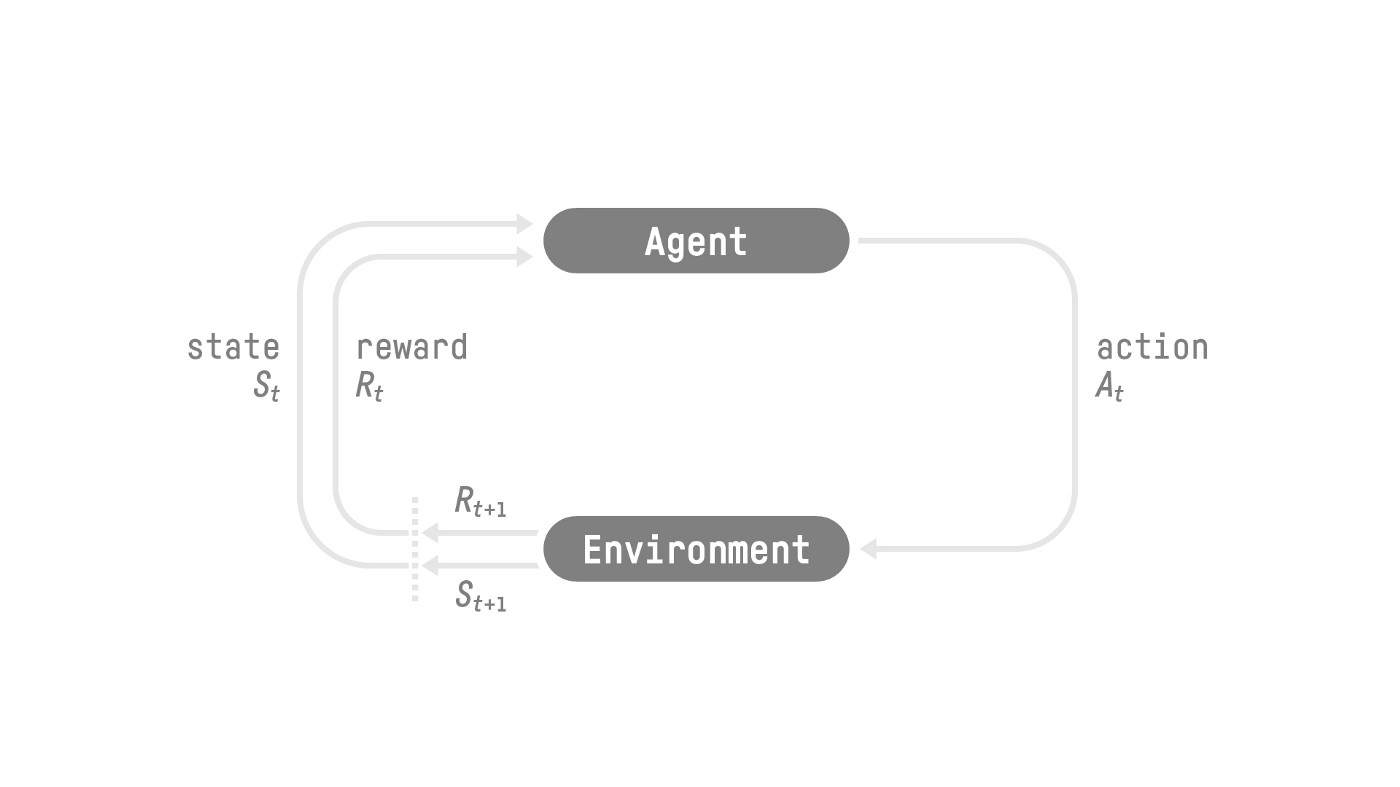
The RL Process: a loop of state, action, reward and next state
Source: Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
Now, let’s imagine an agent learning to play a platform game. The RL process looks like this:
RL过程RL过程:状态、动作、奖励和下一个状态的循环来源:强化学习:入门,Richard Sutton和Andrew G.Barto现在,让我们想象一个代理学习玩平台游戏。RL流程如下所示:
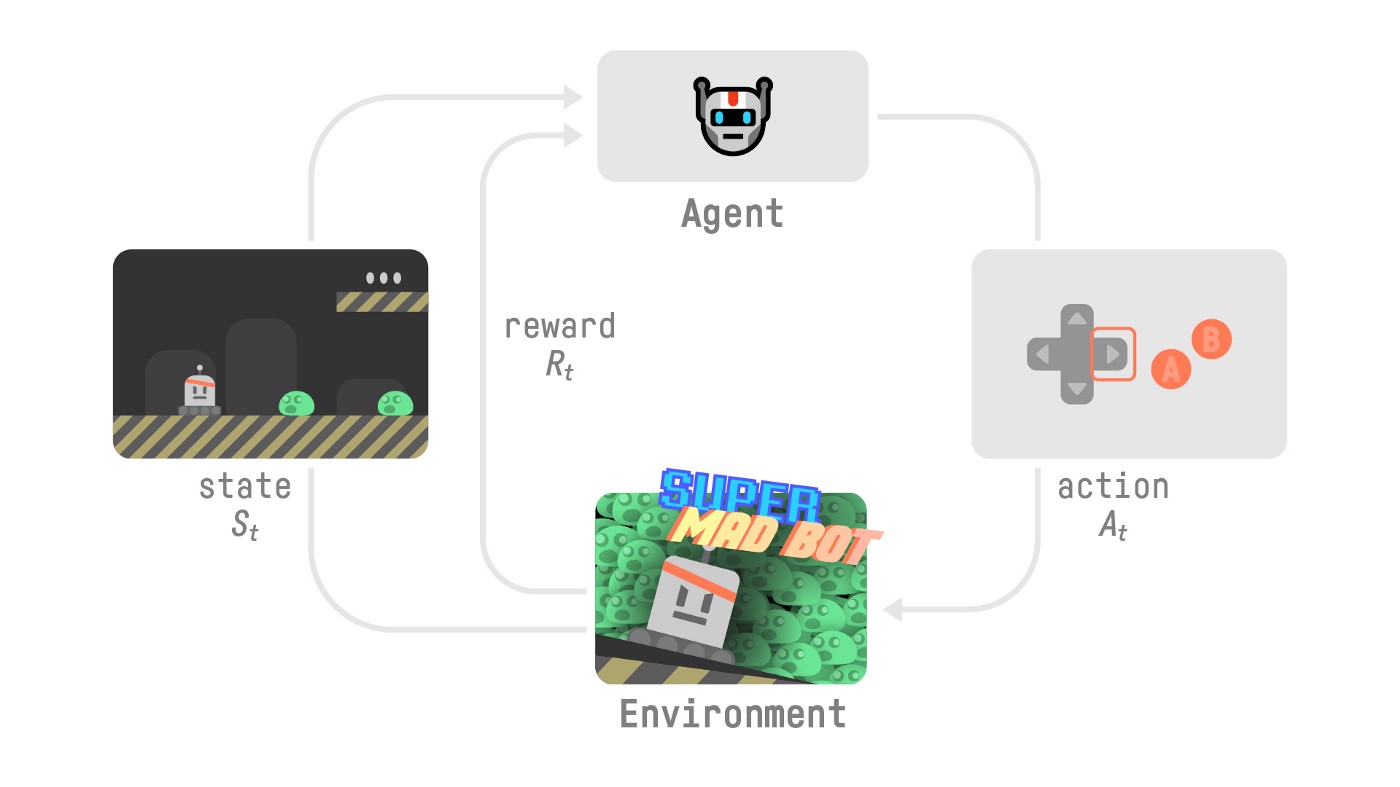
RL流程
- Our Agent receives state S0S_0S0 from the Environment — we receive the first frame of our game (Environment).
- Based on that state S0S_0S0, the Agent takes action A0A_0A0 — our Agent will move to the right.
- Environment goes to a new state S1S_1S1 — new frame.
- The environment gives some reward R1R_1R1 to the Agent — we’re not dead (Positive Reward +1).
This RL loop outputs a sequence of state, action, reward and next state. The goal of the agent is to maximize the expected cumulative reward.
我们的代理从新环境收到状态S0S_0S0-我们收到游戏的第一帧(环境)。基于该状态S0S_0S0,如果代理采取行动A0A_0A0,我们的代理将向右移动。环境进入一个新的状态S1S_1s1-新的框架。环境给代理一些新的奖励R1R_1R1-我们没有死(正奖励+1)。这个RL循环输出状态、动作、奖励和下一个状态的序列。代理人的目标是最大化期望的累积报酬。
The Academy will be the one that will send the order to our Agents and ensure that agents are in sync:
学院将向我们的代理发送订单,并确保代理同步:
- Collect Observations
- Select your action using your policy
- Take the Action
- Reset if you reached the max step or if you’re done.
Now that we understand how ML-Agents works, we’re ready to train our agents.
收集观察使用您的策略选择您的操作如果您已达到最大步数或已完成,请执行操作重置。MLAgents Academy现在我们了解了ML-Agents的工作原理,我们准备好培训我们的代理。