H7-Unit_4-Policy_Gradient_with_PyTorch-B1-based_methods
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit8/introduction?fw=pt
What are the policy-based methods?
以政策为基础的方法有哪些?
The main goal of Reinforcement learning is to find the optimal policy π∗\pi^{*}π∗ that will maximize the expected cumulative reward.
Because Reinforcement Learning is based on the reward hypothesis: all goals can be described as the maximization of the expected cumulative reward.
强化学习的主要目标是找到使期望累积报酬最大化的∗∗ππ策略。因为强化学习是建立在报酬假设的基础上的:所有的目标都可以用期望累积报酬的最大化来描述。
For instance, in a soccer game (where you’re going to train the agents in two units), the goal is to win the game. We can describe this goal in reinforcement learning as
maximizing the number of goals scored (when the ball crosses the goal line) into your opponent’s soccer goals. And minimizing the number of goals in your soccer goals.
例如,在一场足球比赛中(您将在两个单元中训练代理),目标是赢得比赛。在强化学习中,我们可以将这个目标描述为最大化进球的数量(当球越过球门线时)进入对手的足球球门。将你的足球进球数量降到最低。

足球
Value-based, Policy-based, and Actor-critic methods
基于价值、基于政策和参与者批评的方法
We studied in the first unit, that we had two methods to find (most of the time approximate) this optimal policy π∗\pi^{*}π∗.
在第一单元中,我们研究了两种方法来寻找(大部分时间是近似的)∗∗ππ策略的最优策略。
In value-based methods, we learn a value function.
在基于价值的方法中,我们学习价值函数。
- The idea is that an optimal value function leads to an optimal policy π∗\pi^{*}π∗.
- Our objective is to minimize the loss between the predicted and target value to approximate the true action-value function.
- We have a policy, but it’s implicit since it was generated directly from the value function. For instance, in Q-Learning, we defined an epsilon-greedy policy.
On the other hand, in policy-based methods, we directly learn to approximate π∗\pi^{*}π∗ without having to learn a value function.
我们的想法是,最优值函数导致最优策略∗∗ππ.我们的目标是最小化预测值和目标值之间的损失,以接近真实的行动值函数.我们有一个策略,但它是隐含的,因为它是直接从值函数生成的.例如,在Q-学习中,我们定义了一个epsilon-贪婪策略;另一方面,在基于策略的方法中,我们不需要学习值函数就可以直接学习逼近∗∗ππ。
- The idea is to parameterize the policy. For instance, using a neural network πθ\pi_\thetaπθ, this policy will output a probability distribution over actions (stochastic policy).

- Our objective then is to maximize the performance of the parameterized policy using gradient ascent.
- To do that, we control the parameter θ\thetaθ that will affect the distribution of actions over a state.
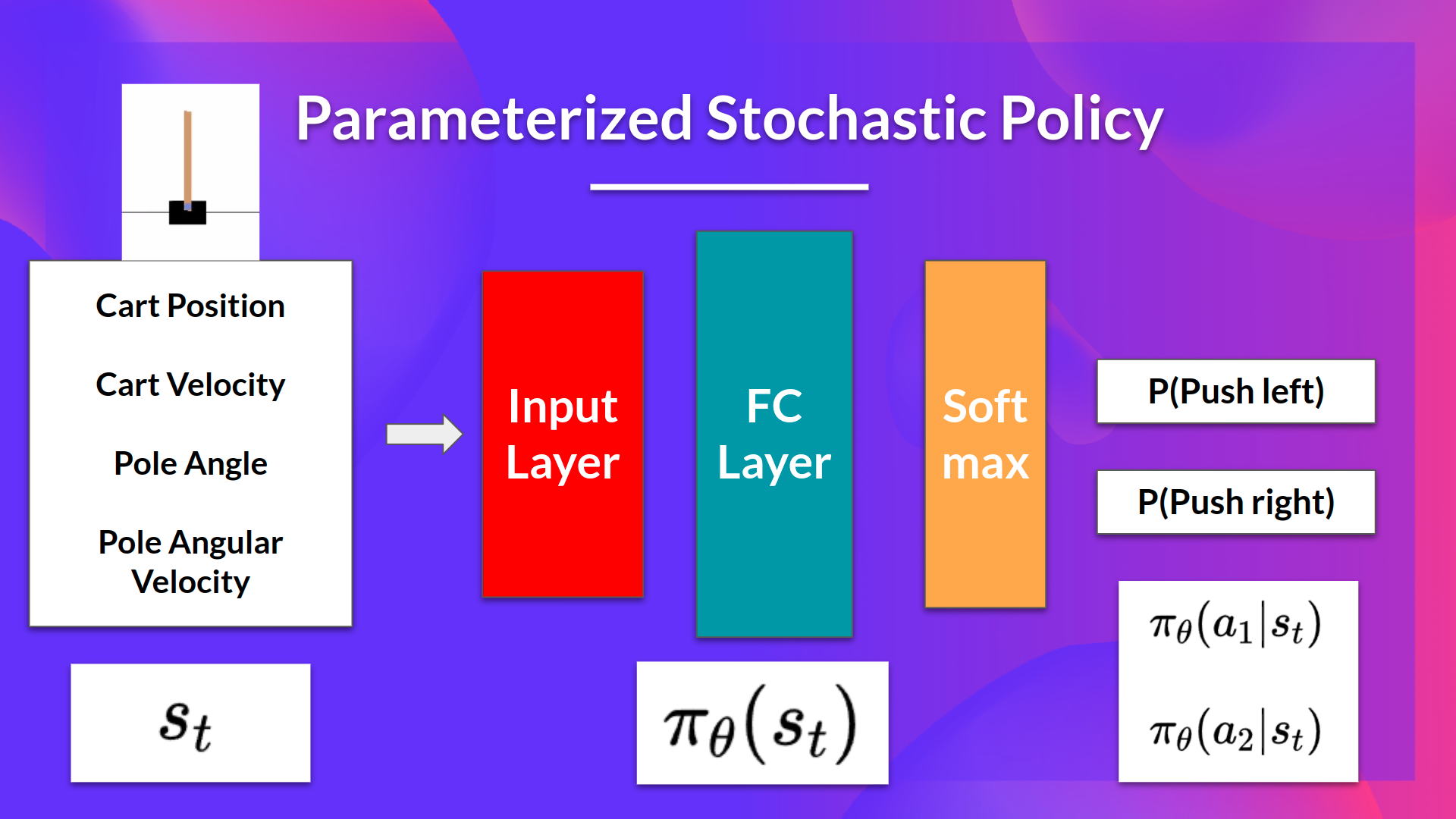
我们的想法是将政策参数化。例如,使用神经网络πθ\pi_\thetaπθθ,此策略将输出动作的概率分布(随机策略)。随机策略我们的目标是使用梯度上升最大化参数化策略的性能。为此,我们控制参数πθ\thetaπθ,它将影响动作在状态上的分布。基于策略
- Finally, we’ll study the next time actor-critic which is a combination of value-based and policy-based methods.
Consequently, thanks to policy-based methods, we can directly optimize our policy πθ\pi_\thetaπθ to output a probability distribution over actions πθ(a∣s)\pi_\theta(a|s)πθ(a∣s) that leads to the best cumulative return.
To do that, we define an objective function J(θ)J(\theta)J(θ), that is, the expected cumulative reward, and we want to find θ\thetaθ that maximizes this objective function.
最后,我们将研究基于价值的方法和基于策略的方法相结合的下一次参与者-批评者。因此,由于基于策略的方法,我们可以直接优化我们的策略πθ\pi_\πθπθ(aπθs)\pi_\theta(a|s)πθ(aπθs)(a∣s)(aπθπθ(aπθs)),从而获得最好的累积收益。为此,我们定义了一个目标函数J(θ)J(\theta)J(θ),即期望累积报酬,并且我们希望找到使该目标函数最大化的θ\thetaθ。
The difference between policy-based and policy-gradient methods
基于政策的方法与基于政策的梯度方法的区别
Policy-gradient methods, what we’re going to study in this unit, is a subclass of policy-based methods. In policy-based methods, the optimization is most of the time on-policy since for each update, we only use data (trajectories) collected by our most recent version of πθ\pi_\thetaπθ.
我们将在本单元中学习的政策梯度方法是基于政策的方法的一个子类。在基于策略的方法中,优化大部分时间是按策略进行的,因为对于每次更新,我们只使用由最新版本的πθ\pi_\thetaπθ收集的数据(轨迹)。
The difference between these two methods lies on how we optimize the parameter θ\thetaθ:
这两种方法的区别在于我们如何优化参数θ\thetaθ:
- In policy-based methods, we search directly for the optimal policy. We can optimize the parameter θ\thetaθ indirectly by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
- In policy-gradient methods, because it is a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter θ\thetaθ directly by performing the gradient ascent on the performance of the objective function J(θ)J(\theta)J(θ).
Before diving more into how policy-gradient methods work (the objective function, policy gradient theorem, gradient ascent, etc.), let’s study the advantages and disadvantages of policy-based methods.
在基于策略的方法中,我们直接搜索最优策略。我们可以通过爬山、模拟退火法或进化策略最大化目标函数的局部逼近来间接优化参数θ\thetaθ,而在策略梯度方法中,因为它是基于策略的方法的一个子类,所以我们直接搜索最优策略。但我们通过对目标函数J(θ)J(\theta)J(θ)的性能执行梯度上升来直接优化参数θ\thetaθ。在深入研究政策梯度方法如何工作(目标函数、政策梯度定理、梯度上升等)之前,让我们先研究基于政策的方法的优缺点。