F5-Unit_3-Deep_Q_Learning_with_Atari_Games-D3-The_Deep_Q_Algorithm
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit6/hands-on?fw=pt
The Deep Q-Learning Algorithm
深度Q-学习算法
We learned that Deep Q-Learning uses a deep neural network to approximate the different Q-values for each possible action at a state (value-function estimation).
我们了解到,深度Q-学习使用深度神经网络来逼近一个状态下每个可能动作的不同Q值(值函数估计)。
The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
不同之处在于,在训练阶段,不是像我们使用Q-学习所做的那样直接更新状态-动作对的Q值:

in Deep Q-Learning, we create a loss function that compares our Q-value prediction and the Q-target and uses gradient descent to update the weights of our Deep Q-Network to approximate our Q-values better.
Q损失在深度Q学习中,我们创建一个损失函数,将我们的Q值预测与Q目标进行比较,并使用梯度下降来更新我们的深度Q网络的权重,以更好地逼近我们的Q值。

The Deep Q-Learning training algorithm has two phases:
Q目标深度Q-学习训练算法有两个阶段:
- Sampling: we perform actions and store the observed experience tuples in a replay memory.
- Training: Select a small batch of tuples randomly and learn from this batch using a gradient descent update step.

This is not the only difference compared with Q-Learning. Deep Q-Learning training might suffer from instability, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
采样:我们执行动作并将观察到的经验元组存储在回放存储器中。训练:随机选择一小批元组,并使用梯度下降更新步骤从这批学习中学习。采样训练与Q-学习相比,这并不是唯一的区别。深度Q-学习训练可能会受到不稳定的影响,主要是因为结合了非线性Q值函数(神经网络)和自举(当我们使用现有估计而不是实际的完整回报来更新目标时)。
To help us stabilize the training, we implement three different solutions:
为了帮助我们稳定培训,我们实施了三种不同的解决方案:
- Experience Replay to make more efficient use of experiences.
- Fixed Q-Target to stabilize the training.
- Double Deep Q-Learning, to handle the problem of the overestimation of Q-values.
Let’s go through them!
经验回放,更有效地利用经验。固定Q-目标,稳定训练。双深度Q-学习,处理Q值高估的问题。让我们来看看它们!
Experience Replay to make more efficient use of experiences
体验回放,更有效地利用体验
Why do we create a replay memory?
为什么我们要创造一个回放记忆?
Experience Replay in Deep Q-Learning has two functions:
深度问答学习中的体验回放有两个功能:
- Make more efficient use of the experiences during the training.
Usually, in online reinforcement learning, the agent interacts in the environment, gets experiences (state, action, reward, and next state), learns from them (updates the neural network), and discards them. This is not efficient
Experience replay helps using the experiences of the training more efficiently. We use a replay buffer that saves experience samples that we can reuse during the training.
更有效地利用培训过程中的经验。通常,在在线强化学习中,代理在环境中交互,获得经验(状态、动作、奖励和下一个状态),从中学习(更新神经网络),然后丢弃它们。经验回放有助于更有效地利用培训经验。我们使用一个回放缓冲区来保存我们可以在培训期间重复使用的经验样本。

⇒ This allows the agent to learn from the same experiences multiple times.
体验重播⇒这允许工程师多次学习相同的体验。
- Avoid forgetting previous experiences and reduce the correlation between experiences.
- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget the previous experiences as it gets new experiences. For instance, if the agent is in the first level and then in the second, which is different, it can forget how to behave and play in the first level.
The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents the network from only learning about what it has done immediately before.
避免忘记以前的经验,降低经验之间的相关性。如果我们将连续的经验样本提供给我们的神经网络,我们得到的问题是,当它获得新的经验时,它往往会忘记以前的经验。例如,如果代理处于第一级,然后在第二级,这是不同的,它可能会忘记如何在第一级表现和发挥作用。解决方案是创建一个重放缓冲区,在与环境交互时存储经验元组,然后采样一小批元组。这避免了网络只了解它之前做过的事情。
Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid action values from oscillating or diverging catastrophically.
体验回放还有其他好处。通过随机抽样经验,我们消除了观测序列中的相关性,避免了动作值的灾难性振荡或发散。
In the Deep Q-Learning pseudocode, we initialize a replay memory buffer D from capacity N (N is a hyperparameter that you can define). We then store experiences in the memory and sample a batch of experiences to feed the Deep Q-Network during the training phase.
在深度Q-学习伪代码中,我们从容量N(N是您可以定义的超参数)初始化重放内存缓冲区D。然后,我们将经验存储在内存中,并在训练阶段对一批经验进行采样,以提供给Deep Q-Network。

体验重播伪码
Fixed Q-Target to stabilize the training
固定Q-目标以稳定训练
When we want to calculate the TD error (aka the loss), we calculate the difference between the TD target (Q-Target) and the current Q-value (estimation of Q).
当我们想要计算TD误差(又名损失)时,我们计算TD目标(Q-Target)和当前Q值(Q的估计)之间的差值。
But we don’t have any idea of the real TD target. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
但我们对真实的TD目标一无所知。我们需要对其进行估计。利用贝尔曼方程,我们看到TD目标就是在那个州采取行动的回报加上下一个州的贴现最高Q值。
However, the problem is that we are using the same parameters (weights) for estimating the TD target and the Q-value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
然而,问题是我们使用相同的参数(权重)来估计TD目标和Q值。因此,TD目标和我们正在改变的参数之间存在显著的相关性。
Therefore, it means that at every step of training, our Q-values shift but also the target value shifts. We’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This can lead to a significant oscillation in training.
因此,这意味着在训练的每一步,我们的Q值都在移动,目标值也在移动。我们离目标越来越近,但目标也在移动。这就像在追逐一个移动的目标!这可能会导致训练中的显著波动。
It’s like if you were a cowboy (the Q estimation) and you want to catch the cow (the Q-target). Your goal is to get closer (reduce the error).
这就像如果你是一个牛仔(Q估计),而你想要抓住奶牛(Q目标)。您的目标是更接近(减少错误)。
At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
Q-目标在每个时间步,你试图接近奶牛,它也在每个时间步移动(因为你使用相同的参数)。


This leads to a bizarre path of chasing (a significant oscillation in training).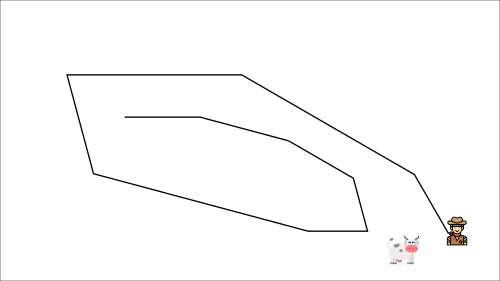
Instead, what we see in the pseudo-code is that we:
Q目标Q目标这导致了一条奇怪的追逐路径(训练中的一种显著的振荡)。Q目标相反,我们在伪代码中看到的是我们:
- Use a separate network with fixed parameters for estimating the TD Target
- Copy the parameters from our Deep Q-Network at every C step to update the target network.

使用具有固定参数的单独网络来估计TD目标在每C步从我们的深度Q-网络复制参数以更新目标网络。固定Q-目标伪码
Double DQN
双DQN
Double DQNs, or Double Learning, were introduced by Hado van Hasselt. This method handles the problem of the overestimation of Q-values.
双重DQN,或双重学习,是由Hado van Hasselt引入的。这种方法很好地解决了Q值被高估的问题。
To understand this problem, remember how we calculate the TD Target:
要理解这个问题,请记住我们是如何计算TD目标的:

We face a simple problem by calculating the TD target: how are we sure that the best action for the next state is the action with the highest Q-value?
TD目标我们通过计算TD目标面临一个简单的问题:我们如何确定下一个状态的最佳动作是Q值最高的动作?
We know that the accuracy of Q-values depends on what action we tried and what neighboring states we explored.
我们知道,Q值的准确性取决于我们尝试了什么行动,以及我们探索了哪些邻近国家。
Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q-value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly given a higher Q value than the optimal best action, the learning will be complicated.
因此,我们没有足够的信息来说明在培训开始时应该采取的最佳行动。因此,将最大Q值(噪声较大)作为最佳操作可能会导致误报。如果经常给非最优动作赋予比最优最佳动作更高的Q值,则学习将是复杂的。
The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q-value generation. We:
解决方案是:当我们计算Q目标时,我们使用两个网络来将动作选择与目标Q值生成分离。我们:
- Use our DQN network to select the best action to take for the next state (the action with the highest Q-value).
- Use our Target network to calculate the target Q-value of taking that action at the next state.
Therefore, Double DQN helps us reduce the overestimation of Q-values and, as a consequence, helps us train faster and have more stable learning.
使用我们的DQN网络来选择下一个状态下要采取的最佳动作(具有最高Q值的动作)。使用我们的Target网络来计算在下一个状态下采取该动作的目标Q值。因此,Double DQN帮助我们减少对Q值的高估,从而帮助我们训练得更快,学习更稳定。
Since these three improvements in Deep Q-Learning, many have been added such as Prioritized Experience Replay, Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list.
自从深度Q-学习的这三个改进之后,又增加了许多,比如优先体验重播,决斗深度Q-学习。它们超出了本课程的范围,但如果您感兴趣,请查看我们在阅读列表中提供的链接。