F5-Unit_3-Deep_Q_Learning_with_Atari_Games-C2-Network_(DQN)
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit6/advantage-actor-critic?fw=pt
The Deep Q-Network (DQN)
深度Q-网络(DQN)
This is the architecture of our Deep Q-Learning network: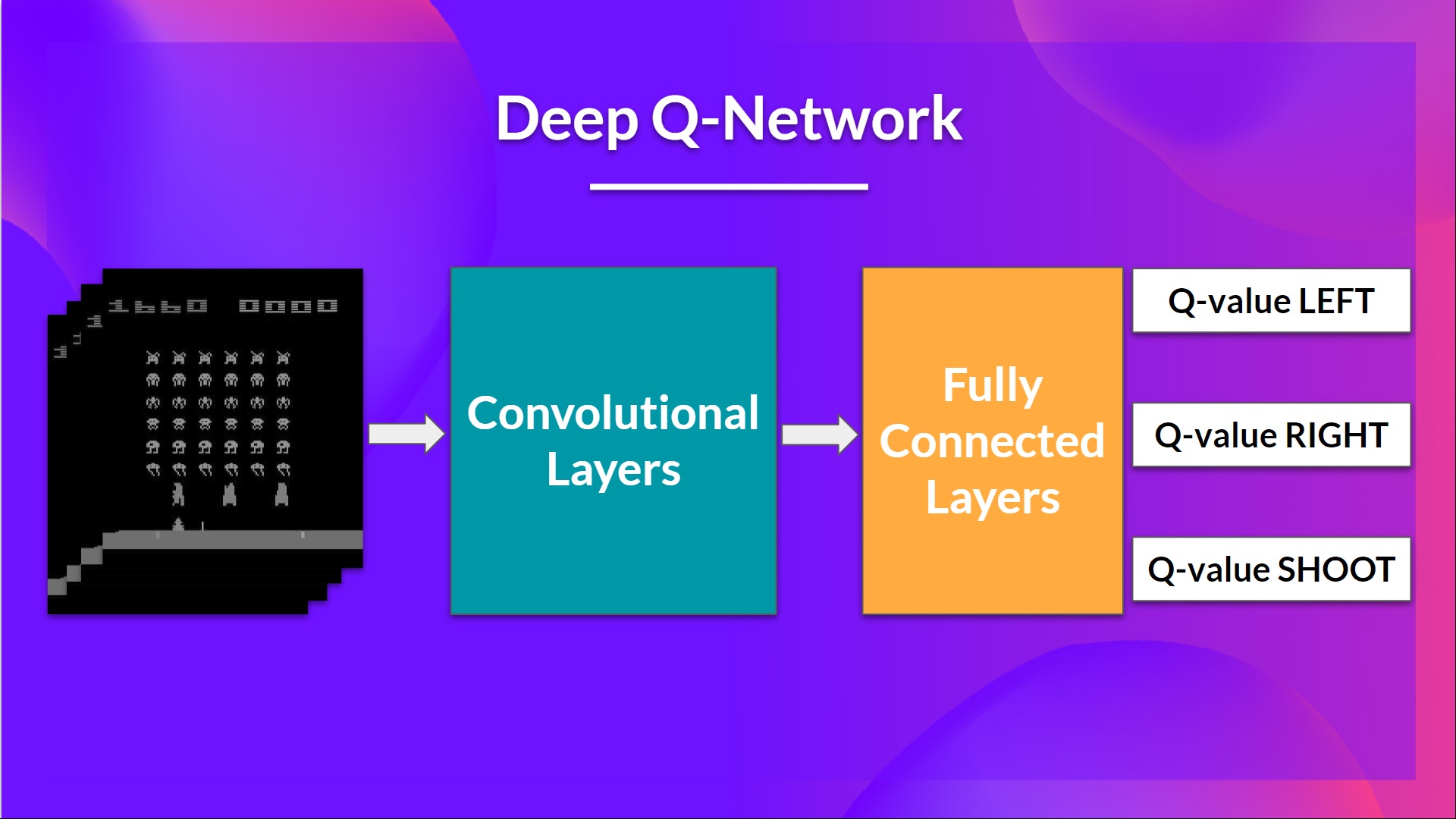
As input, we take a stack of 4 frames passed through the network as a state and output a vector of Q-values for each possible action at that state. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
这是我们的深度Q-学习网络的体系结构:深度Q网络作为输入,我们将通过网络传递的4个帧的堆栈作为状态,并输出该状态下每个可能动作的Q值向量。然后,就像Q-Learning一样,我们只需要使用贪婪的策略来选择要采取的操作。
When the Neural Network is initialized, the Q-value estimation is terrible. But during training, our Deep Q-Network agent will associate a situation with appropriate action and learn to play the game well.
当神经网络被初始化时,Q值估计很差。但在训练期间,我们的Deep Q-Network工程师会将一种情况与适当的行动联系起来,并学习如何玩好这个游戏。
Preprocessing the input and temporal limitation
输入和时间限制的前处理
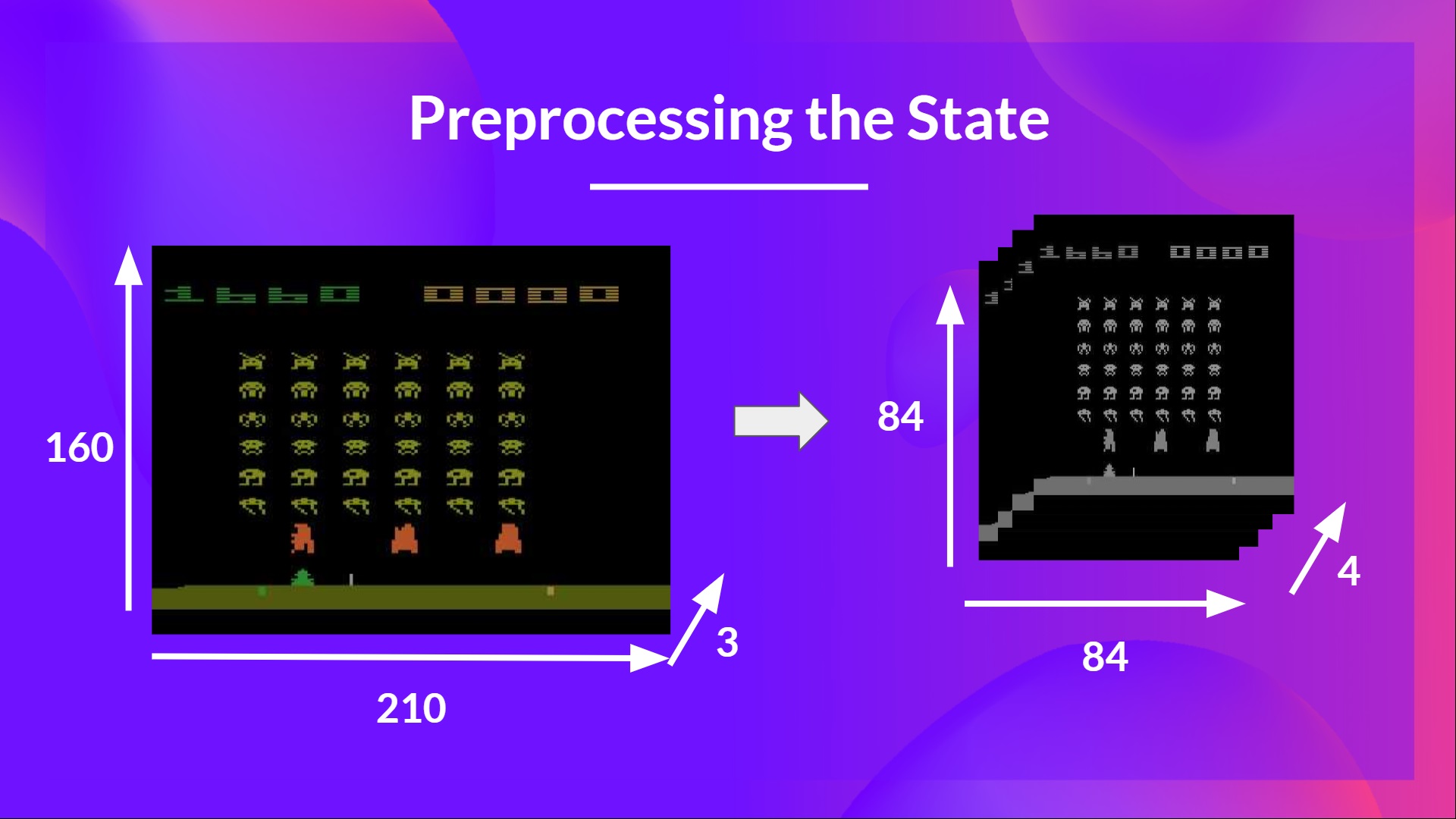
We need to preprocess the input. It’s an essential step since we want to reduce the complexity of our state to reduce the computation time needed for training.
我们需要对输入进行预处理。这是必不可少的一步,因为我们想要降低状态的复杂性,以减少训练所需的计算时间。
To achieve this, we reduce the state space to 84x84 and grayscale it. We can do this since the colors in Atari environments don’t add important information.
This is an essential saving since we reduce our three color channels (RGB) to 1.
为了实现这一点,我们将状态空间减少到84x84并将其灰度化。我们可以做到这一点,因为雅达利环境中的颜色不会添加重要信息。这是一项重要的节省,因为我们将三个颜色通道(RGB)减少到1。
We can also crop a part of the screen in some games if it does not contain important information.
Then we stack four frames together.
我们还可以在一些游戏中裁剪屏幕的一部分,如果它不包含重要信息。然后我们把四个相框叠在一起。
Why do we stack four frames together?
We stack frames together because it helps us handle the problem of temporal limitation. Let’s take an example with the game of Pong. When you see this frame:
预处理为什么我们要将四个帧堆叠在一起?我们将帧堆叠在一起是因为它帮助我们处理时间限制的问题。让我们以乒乓球游戏为例。当您看到此帧时:

Can you tell me where the ball is going?
No, because one frame is not enough to have a sense of motion! But what if I add three more frames? Here you can see that the ball is going to the right.
时间限制你能告诉我球要去哪里吗?不,因为一帧画面不足以产生动感!但如果我再添加三个帧呢?在这里你可以看到球是向右飞的。

That’s why, to capture temporal information, we stack four frames together.
Then, the stacked frames are processed by three convolutional layers. These layers allow us to capture and exploit spatial relationships in images. But also, because frames are stacked together, you can exploit some temporal properties across those frames.
时间限制这就是为什么,为了捕捉时间信息,我们将四个帧堆叠在一起。然后,通过三个卷积层对堆叠的帧进行处理。这些层允许我们捕捉和利用图像中的空间关系。而且,因为帧是堆叠在一起的,所以您可以利用这些帧的一些时间属性。
If you don’t know what are convolutional layers, don’t worry. You can check the Lesson 4 of this free Deep Reinforcement Learning Course by Udacity
如果你不知道什么是卷积层,也不用担心。你可以通过Udacity查看这个免费的深度强化学习课程的第四课
Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
最后,我们有两个完全连接的层,它们为该状态下的每个可能的操作输出一个Q值。
So, we see that Deep Q-Learning is using a neural network to approximate, given a state, the different Q-values for each possible action at that state. Let’s now study the Deep Q-Learning algorithm.
深度Q网络所以,我们看到深度Q-学习是使用神经网络来近似,给定一个状态,在该状态下每个可能的动作的不同Q值。现在我们来研究深度Q-学习算法。