E4-Unit_2-Introduction_to_Q_Learning-M12-Q_Learning_Quiz
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit4/quiz?fw=pt
Second Quiz
第二次测验
The best way to learn and to avoid the illusion of competence is to test yourself. This will help you to find where you need to reinforce your knowledge.
学习和避免能力幻觉的最好方法是测试自己。这将帮助你找到你需要加强知识的地方。
Q1: What is Q-Learning?
Q1:什么是Q-Learning?
The algorithm we use to train our Q-function
我们用来训练Q函数的算法
A value function
值函数
An algorithm that determines the value of being at a particular state and taking a specific action at that state
确定处于特定状态并在该状态下执行特定操作的值的算法
A table
一张桌子
Q2: What is a Q-table?
问2:什么是Q表?
An algorithm we use in Q-Learning
Q-学习中的一种算法
Q-table is the internal memory of our agent
Q表是我们代理的内部存储器
In Q-table each cell corresponds a state value
在Q表中,每个单元格对应一个状态值
Q3: Why if we have an optimal Q-function Q* we have an optimal policy?
问3:为什么我们有一个最优的Q-函数Q*我们有一个最优的策略?
Solution
Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take.
解决方案,因为如果我们有一个最优的Q函数,我们就有了一个最优的策略,因为我们知道每个州采取的最佳行动是什么。

链接值策略
Q4: Can you explain what is Epsilon-Greedy Strategy?
问题4:你能解释一下什么是Epsilon-贪婪战略吗?
Solution
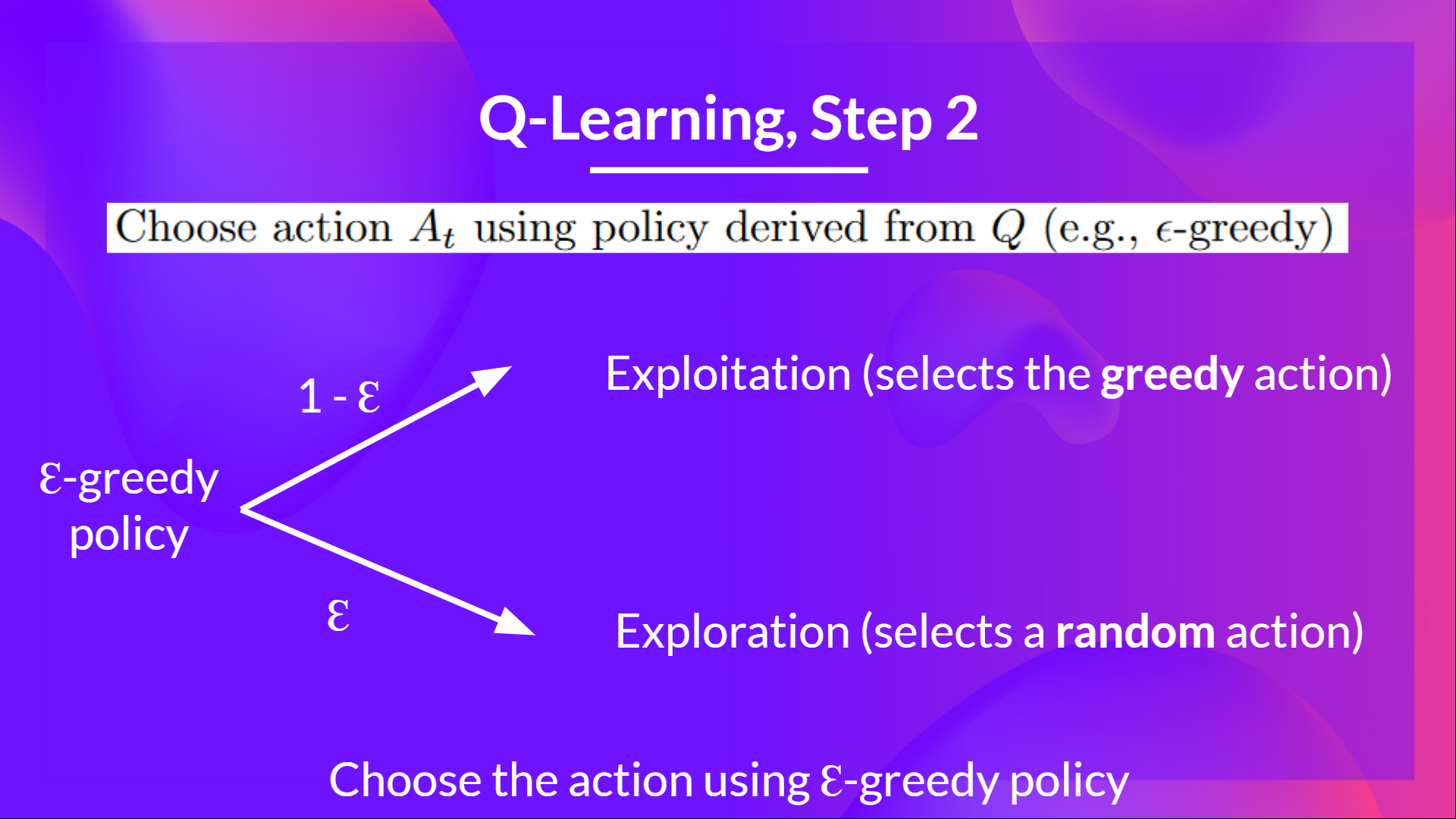
Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.
The idea is that we define epsilon ɛ = 1.0:
解决方案Epsilon贪婪战略是一种处理勘探/开采权衡的政策。我们的想法是,我们定义epsilonɛ=1.0:
- With probability 1 — ɛ : we do exploitation (aka our agent selects the action with the highest state-action pair value).
- With probability ɛ : we do exploration (trying random action).
概率为1-ɛ:我们进行利用(也就是我们的代理选择具有最高状态-操作对值的操作)。概率ɛ:我们进行探索(尝试随机操作)。Epsilon贪婪
Q5: How do we update the Q value of a state, action pair?
问题5:如何更新状态、动作对的Q值?
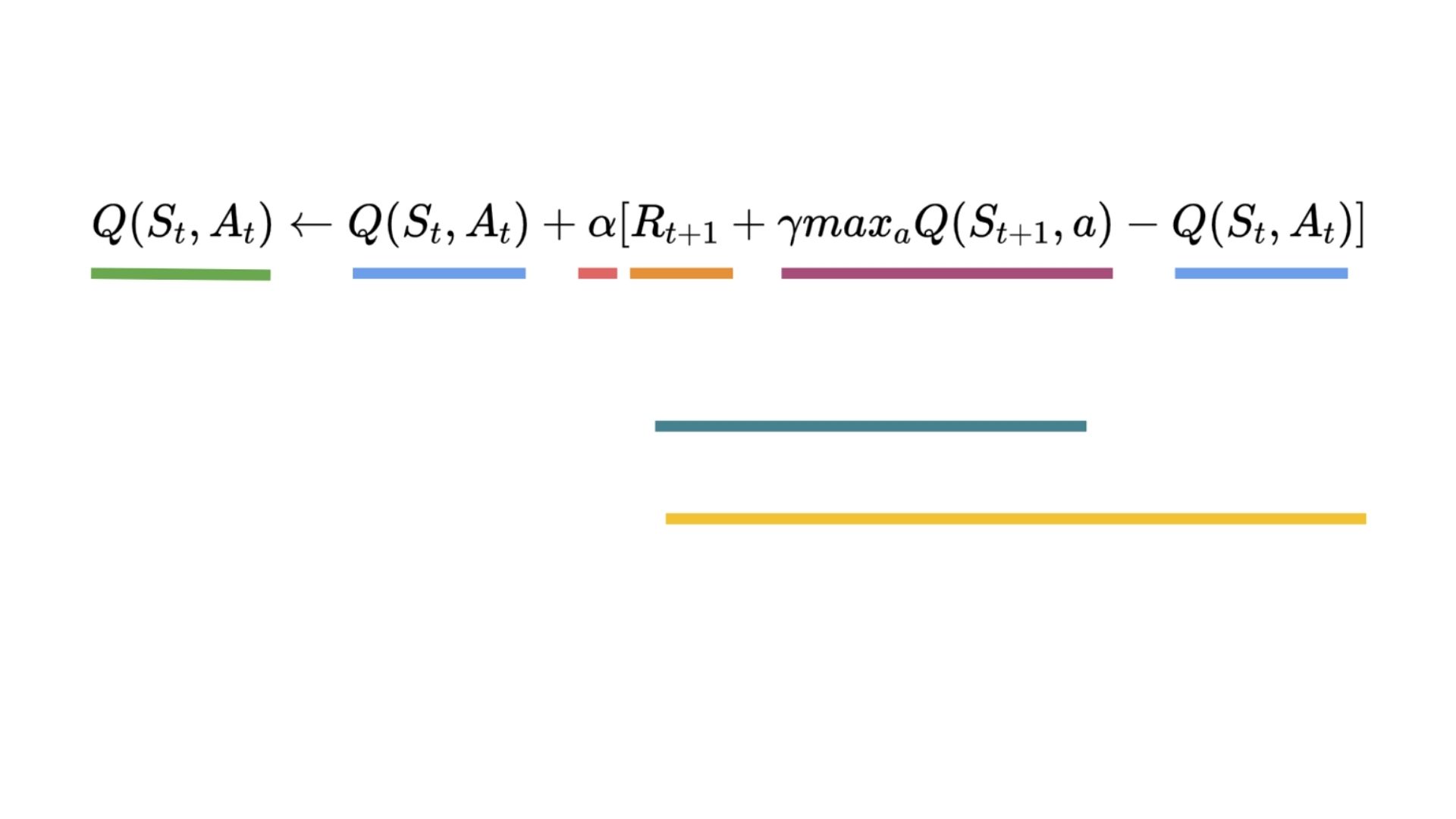
Solution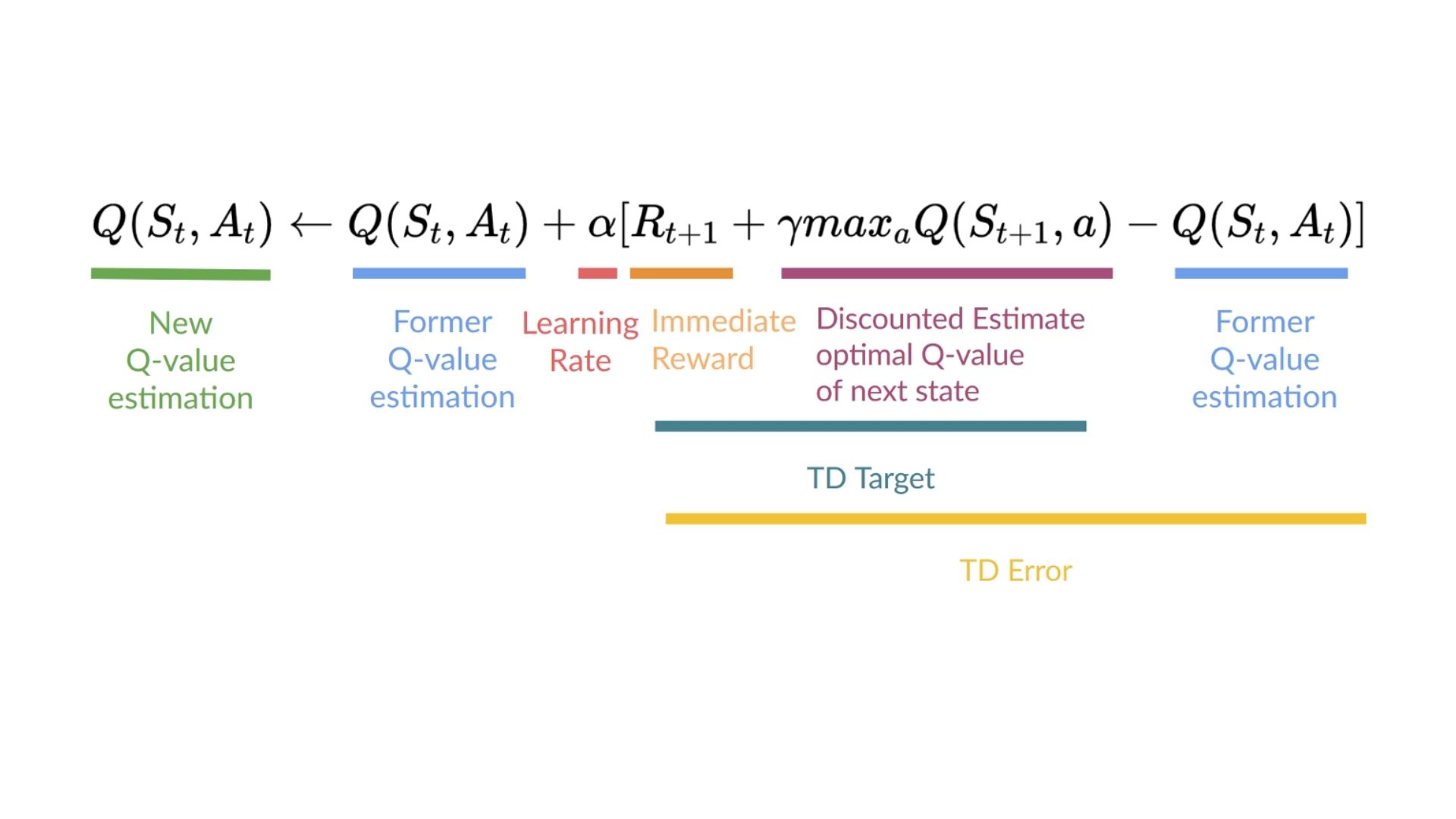
Q更新练习解决方案Q更新练习
Q6: What’s the difference between on-policy and off-policy
问6:政策上和政策外有什么不同
Solution
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
解决方案开/关策略祝贺完成此测验🥳,如果您遗漏了一些元素,请花时间再次阅读本章以巩固(😏)您的知识。