E4-Unit_2-Introduction_to_Q_Learning-J9-Q_Learning_Recap
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit5/conclusion?fw=pt
Q-Learning Recap
Q-学习小结
The Q-Learning is the RL algorithm that :
Q-学习是RL算法,该算法:
- Trains Q-function, an action-value function that contains, as internal memory, a Q-table that contains all the state-action pair values.
- Given a state and action, our Q-function will search into its Q-table the corresponding value.
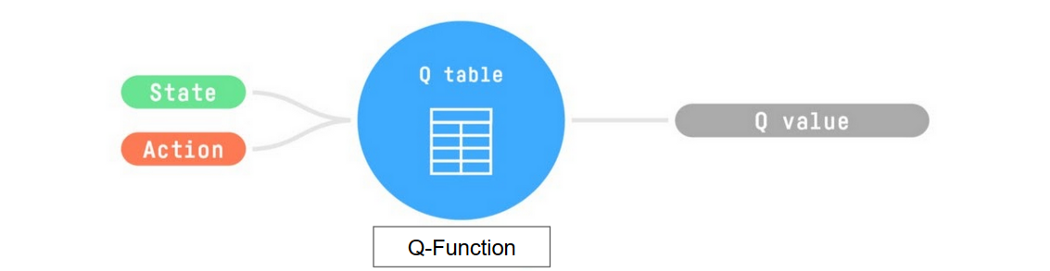
训练Q函数,这是一个动作值函数,它包含一个包含所有状态-动作对值的Q表作为内部存储器。给定一个状态和动作,我们的Q函数将在它的Q表中搜索相应的值。Q函数
- When the training is done,we have an optimal Q-function, so an optimal Q-table.
- And if we have an optimal Q-function, we
have an optimal policy,since we know for each state, what is the best action to take.

But, in the beginning, our Q-table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-table to 0 values). But, as we’ll explore the environment and update our Q-table it will give us better and better approximations
当训练完成时,我们有一个最优的Q-函数,也就是一个最优的Q-表。如果我们有一个最优的Q-函数,我们就有了一个最优的策略,因为我们知道对于每个状态,采取什么是最好的行动。链接值策略。但是,一开始,我们的Q-表是没有用的,因为它给出了每个状态-动作对的任意值。(大多数时候,我们将Q-表初始化为0值)。但是,随着我们继续探索环境并更新我们的Q表,它将给我们越来越好的近似

This is the Q-Learning pseudocode:
Q-learning.jpeg这是Q-Learning伪代码:

Q-学习