E4-Unit_2-Introduction_to_Q_Learning-F5-way_Recap
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit5/pyramids?fw=pt
Mid-way Recap
中途总结
Before diving into Q-Learning, let’s summarize what we just learned.
在深入到Q-Learning之前,让我们总结一下我们刚刚学到的内容。
We have two types of value-based functions:
我们有两种类型的基于值的函数:
- State-value function: outputs the expected return if the agent starts at a given state and acts accordingly to the policy forever after.
- Action-value function: outputs the expected return if the agent starts in a given state, takes a given action at that state and then acts accordingly to the policy forever after.
- In value-based methods, rather than learning the policy, we define the policy by hand and we learn a value function. If we have an optimal value function, we will have an optimal policy.
There are two types of methods to learn a policy for a value function:
状态-值函数:如果代理从给定的状态开始并永远按照策略行事,则输出预期回报。动作-值函数:如果代理在给定的状态开始,在该状态采取给定的操作,然后永远按照策略行事,则输出预期回报。在基于值的方法中,我们不学习策略,而是手工定义策略,并学习值函数。如果我们有一个最优的价值函数,我们就会有一个最优的策略。有两种方法可以学习一个价值函数的策略:
- With the Monte Carlo method, we update the value function from a complete episode, and so we use the actual accurate discounted return of this episode.
- With the TD Learning method, we update the value function from a step, so we replace GtG_tGt that we don’t have with an estimated return called TD target.
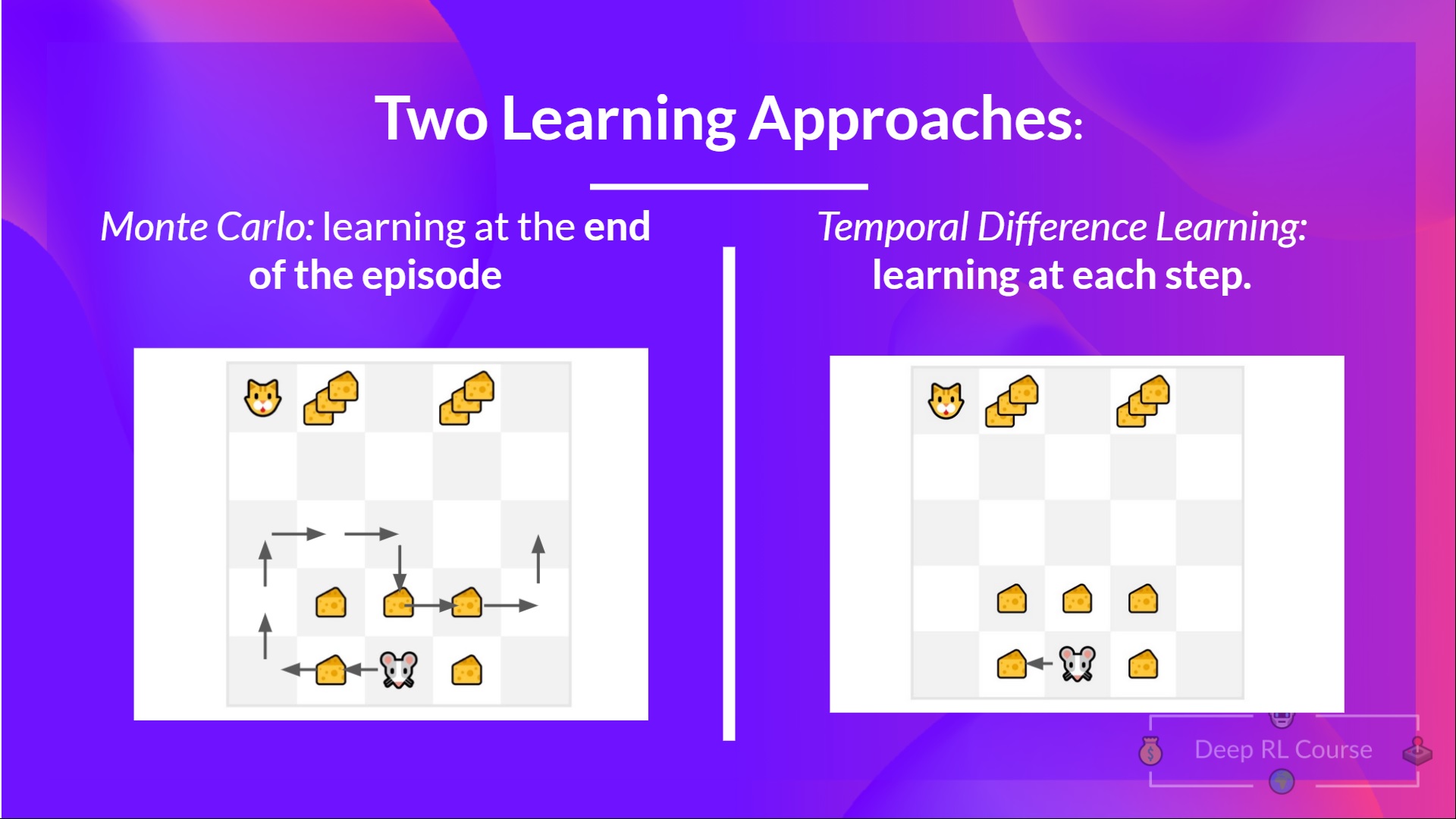
使用蒙特卡罗方法,我们从一个完整的剧集更新值函数,所以我们可以使用这一集的实际准确贴现收益。使用TD学习方法,我们从一个步骤更新值函数,所以我们用一个被称为TD目标的估计收益来代替我们没有的gtg_tgt。