E4-Unit_2-Introduction_to_Q_Learning-B1-What_is_RL_A_short_recap
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit4/policy-gradient?fw=pt
What is RL? A short recap
什么是RL?简要回顾一下
In RL, we build an agent that can make smart decisions. For instance, an agent that learns to play a video game. Or a trading agent that learns to maximize its benefits by deciding on what stocks to buy and when to sell.
在RL中,我们构建了一个能够做出明智决策的代理。例如,一个学会玩电子游戏的经纪人,或者一个学会通过决定买入什么股票和何时卖出来最大化收益的交易代理人。
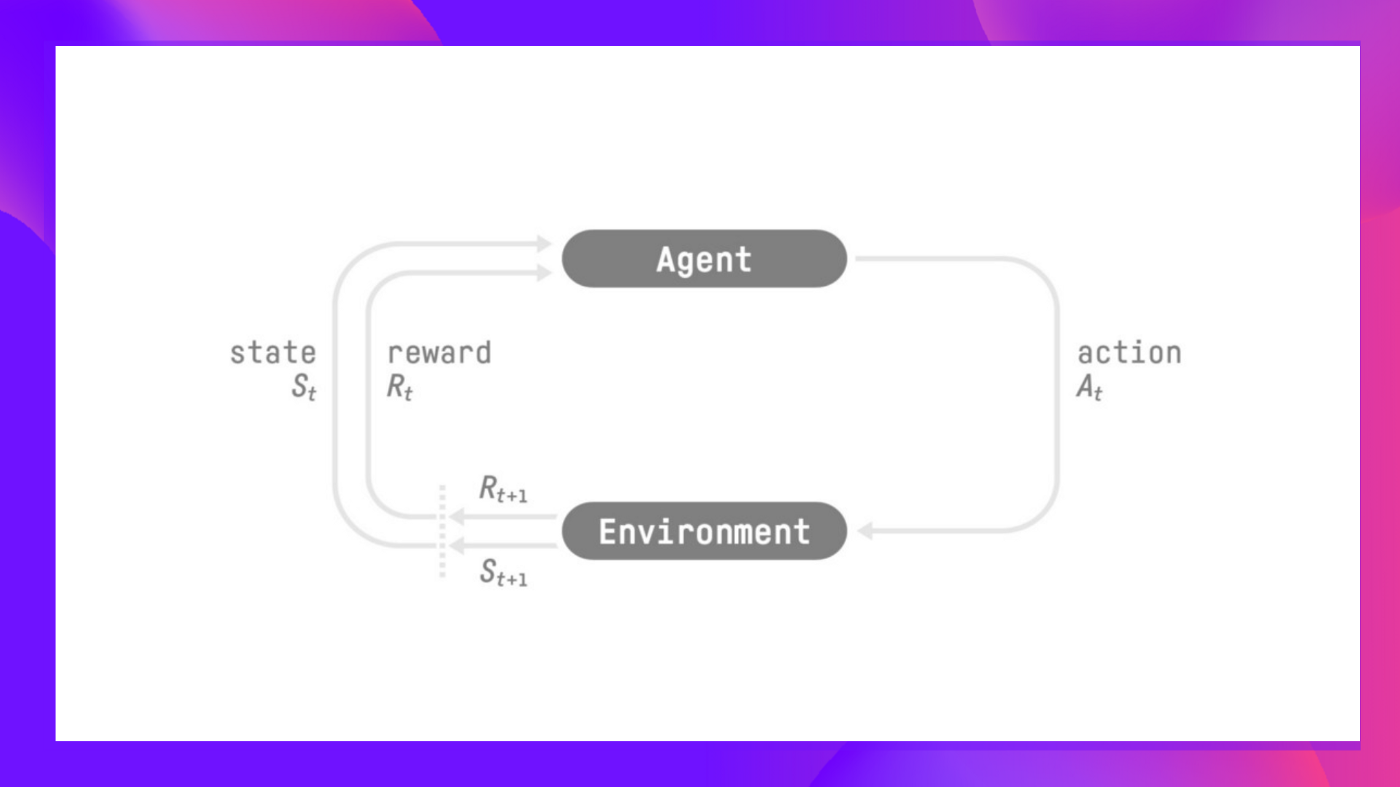
But, to make intelligent decisions, our agent will learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
但是,为了做出智能决策,我们的工程师将从环境中学习,通过反复试验与环境互动,并获得作为独特反馈的奖励(积极或消极)。
Its goal is to maximize its expected cumulative reward (because of the reward hypothesis).
它的目标是最大化其预期的累积奖励收益(因为奖励假说)。
The agent’s decision-making process is called the policy π: given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.
代理的决策过程称为策略π:在给定状态的情况下,策略将输出一个动作或动作上的概率分布。也就是说,给定对环境的观察,策略将提供代理应该采取的操作(或每个操作的多个概率)。

Our goal is to find an optimal policy π* , aka., a policy that leads to the best expected cumulative reward.
策略我们的目标是找到一个最优策略π*,也就是通向最佳预期累积回报的策略。
And to find this optimal policy (hence solving the RL problem), there are two main types of RL methods:
为了找到该最优策略(从而解决RL问题),有两种主要类型的RL方法:
- Policy-based methods: Train the policy directly to learn which action to take given a state.
- Value-based methods: Train a value function to learn which state is more valuable and use this value function to take the action that leads to it.

And in this unit, we’ll dive deeper into the value-based methods.
基于政策的方法:直接训练政策,以了解在给定状态下应该采取哪个行动。基于价值的方法:训练一个值函数,以了解哪个状态更有价值,并使用这个值函数来采取导致它的行动。两种RL方法,在本单元中,我们将更深入地研究基于价值的方法。