B1-Unit_1-Introduction_to_Deep_Reinforcement_Learning-K10-Quiz
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit1/rl-framework?fw=pt
Quiz
小测验
The best way to learn and to avoid the illusion of competence is to test yourself. This will help you to find where you need to reinforce your knowledge.
学习和避免能力幻觉的最好方法是测试自己。这将帮助你找到你需要加强知识的地方。
Q1: What is Reinforcement Learning?
问题1:什么是强化学习?
Solution
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
解决方案强化学习是一种解决控制任务(也称为决策问题)的框架,它通过构建代理来从环境中学习,通过反复尝试与环境交互,并接收作为唯一反馈的奖励(积极或消极)。
Q2: Define the RL Loop
问题2:定义RL循环
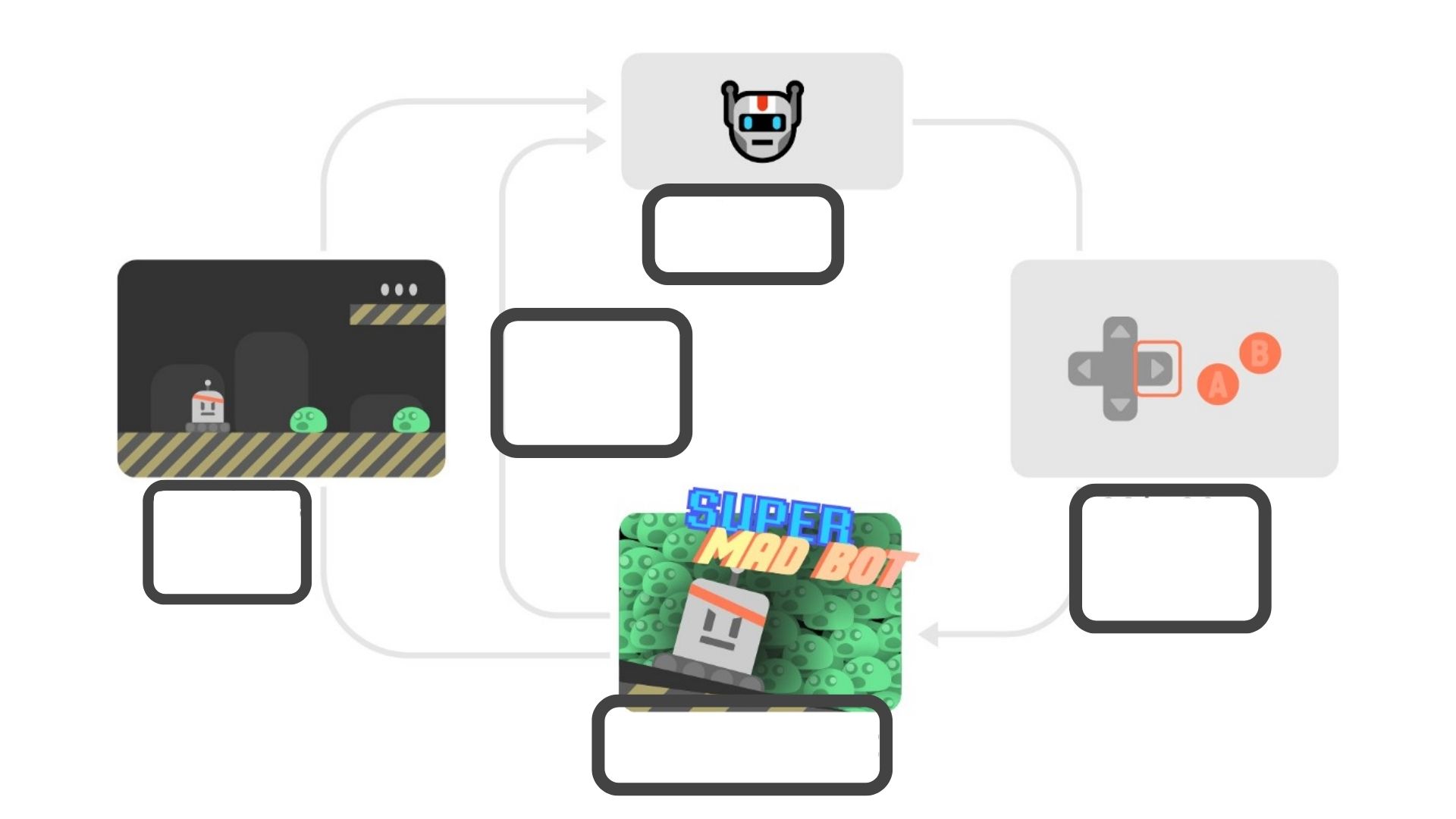
At every step:
练习每一步的RL循环:
- Our Agent receives __ from the environment
- Based on that __ the Agent takes an __
- Our Agent will move to the right
- The Environment goes to a __
- The Environment gives a __ to the Agent
an action a0, action a0, state s0, state s1, reward r1
我们的代理从环境接收_基于__代理采取_我们的代理将向右移动环境将__给予Agentan操作a0、操作a0、状态s0、状态s1、奖励r1
state s0, state s0, action a0, new state s1, reward r1
状态s0、状态s0、动作a0、新状态s1、奖励r1
a state s0, state s0, action a0, state s1, action a1
状态s0、状态s0、动作a0、状态s1、动作a1
Q3: What’s the difference between a state and an observation?
问3:状态和观察有什么不同?
The state is a complete description of the state of the world (there is no hidden information)
状态是对世界状态的完整描述(没有隐藏的信息)
The state is a partial description of the state
状态是对状态的部分描述
The observation is a complete description of the state of the world (there is no hidden information)
观察是对世界状态的完整描述(没有隐藏的信息)
The observation is a partial description of the state
这种观察是对状态的部分描述
We receive a state when we play with chess environment
当我们在国际象棋环境中下棋时,我们会得到一种状态
We receive an observation when we play with chess environment
当我们与国际象棋环境打交道时,我们会得到观察
We receive a state when we play with Super Mario Bros
当我们和超级马里奥兄弟一起玩的时候,我们会得到一种状态
We receive an observation when we play with Super Mario Bros
当我们玩超级马里奥兄弟时,我们会收到一种观察
Q4: A task is an instance of a Reinforcement Learning problem. What are the two types of tasks?
问题4:任务是强化学习问题的一个例子。这两类任务是什么?
Episodic
插曲
Recursive
递归
Adversarial
对抗性的
Continuing
继续
Q5: What is the exploration/exploitation tradeoff?
问题5:勘探/开采的权衡是什么?
Solution
In Reinforcement Learning, we need to balance how much we explore the environment and how much we exploit what we know about the environment.
在强化学习中,我们需要平衡我们对环境的探索程度和我们对环境的了解程度。
- Exploration is exploring the environment by trying random actions in order to find more information about the environment.
- Exploitation is exploiting known information to maximize the reward.
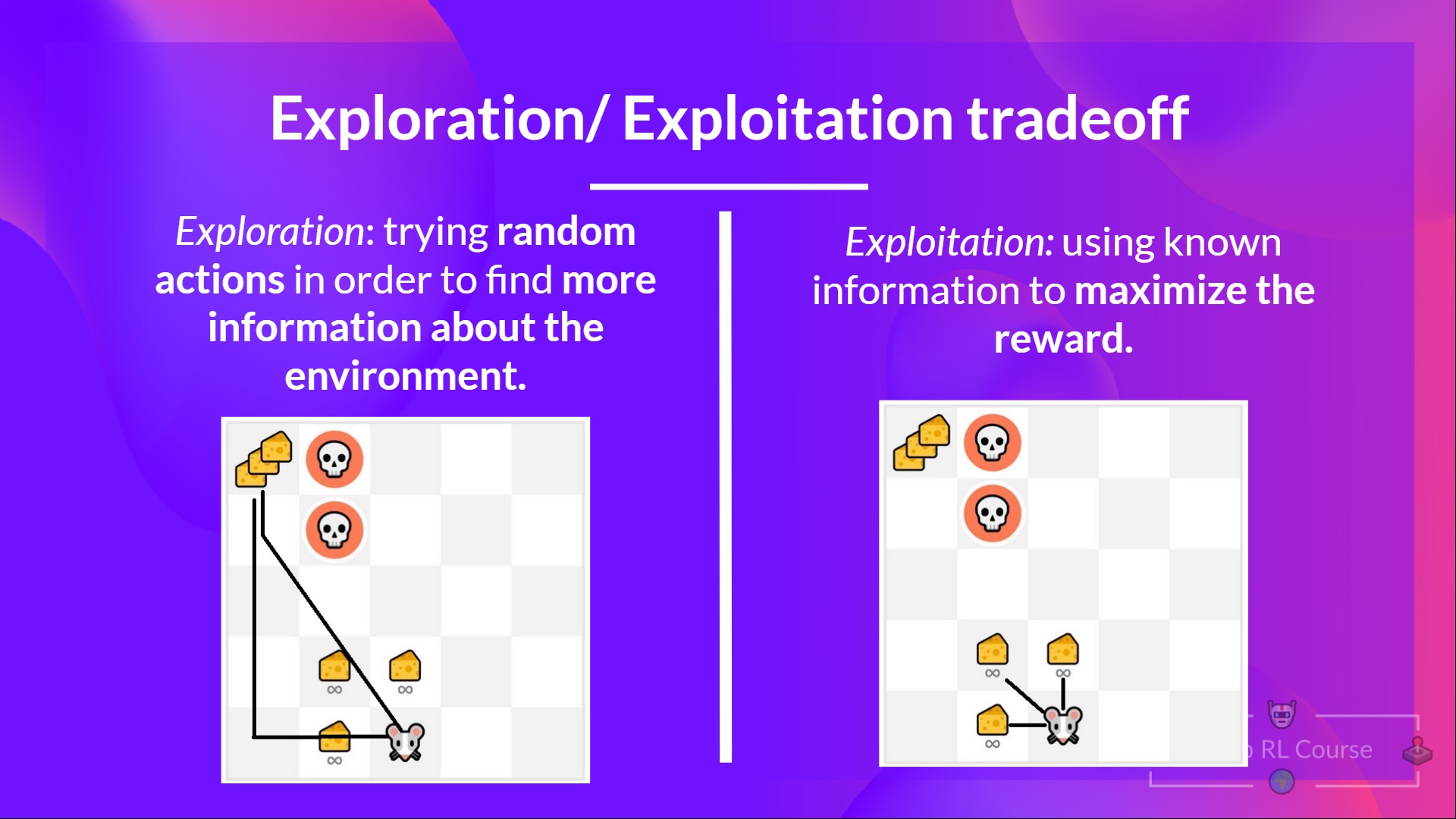
探索是通过尝试随机的行动来探索环境,以找到关于环境的更多信息。开发是利用已知信息来最大化回报。
Q6: What is a policy?
问6:什么是政策?
Solution
解
- The Policy π is the brain of our Agent. It’s the function that tells us what action to take given the state we are in. So it defines the agent’s behavior at a given time.
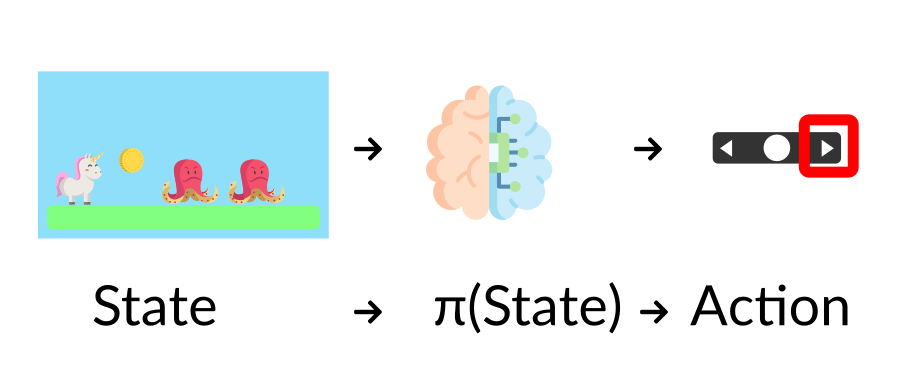
策略π是我们的代理的大脑。它的功能告诉我们,在给定我们所处的状态下,应该采取什么行动。因此它定义了代理在给定时间的行为。策略
Q7: What are value-based methods?
问题7:什么是基于价值的方法?
Solution
解
- Value-based methods is one of the main approaches for solving RL problems.
- In Value-based methods, instead of training a policy function, we train a value function that maps a state to the expected value of being at that state.
Q8: What are policy-based methods?
基于值的方法是解决RL问题的主要方法之一。在基于值的方法中,我们训练的不是策略函数,而是将状态映射到处于该状态的期望值的值函数。问题8:什么是基于策略的方法?
Solution
解
- In Policy-Based Methods, we learn a policy function directly.
- This policy function will map from each state to the best corresponding action at that state. Or a probability distribution over the set of possible actions at that state.
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge, but do not worry: during the course we’ll go over again of these concepts, and you’ll reinforce your theoretical knowledge with hands-on.
在基于策略的方法中,我们直接学习策略函数,该策略函数将从每个状态映射到该状态下的最佳对应动作。或该状态下可能操作集合的概率分布。祝贺您完成本测验🥳,如果您遗漏了一些元素,请花时间再次阅读本章以巩固(😏)您的知识,但不要担心:在本课程中,我们将再次复习这些概念,您将通过动手来巩固您的理论知识。