B1-Unit_1-Introduction_to_Deep_Reinforcement_Learning-C2-The_Reinforcement_Learning_Framework
中英文对照学习,效果更佳!
原课程链接:https://huggingface.co/deep-rl-course/unit1/two-methods?fw=pt
The Reinforcement Learning Framework
强化学习框架
The RL Process
RL流程
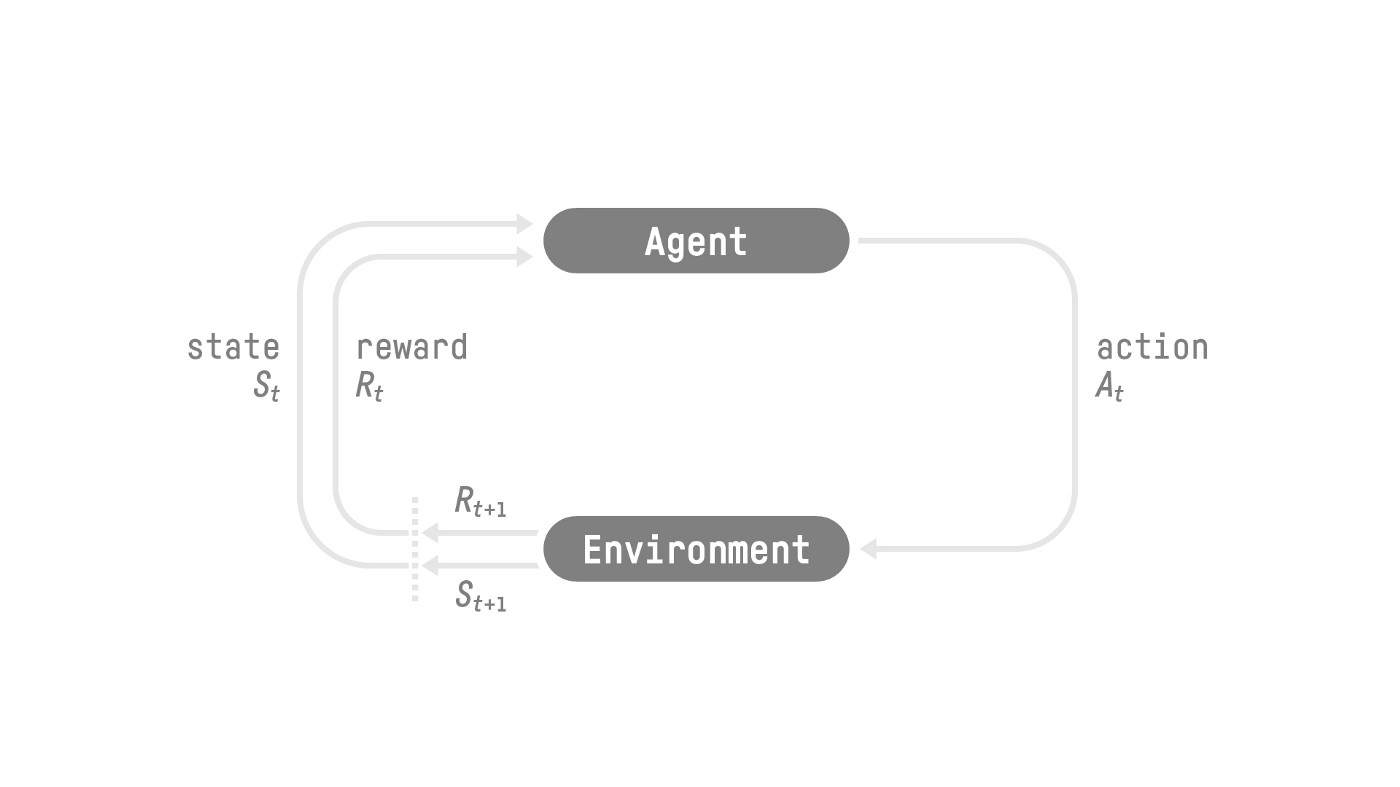
The RL Process: a loop of state, action, reward and next state
Source: Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto
To understand the RL process, let’s imagine an agent learning to play a platform game:
RL过程RL过程:状态、动作、奖励和下一个状态的循环来源:强化学习:简介理查德·萨顿和安德鲁·G·巴托为了理解RL过程,让我们想象一个学习玩平台游戏的代理:
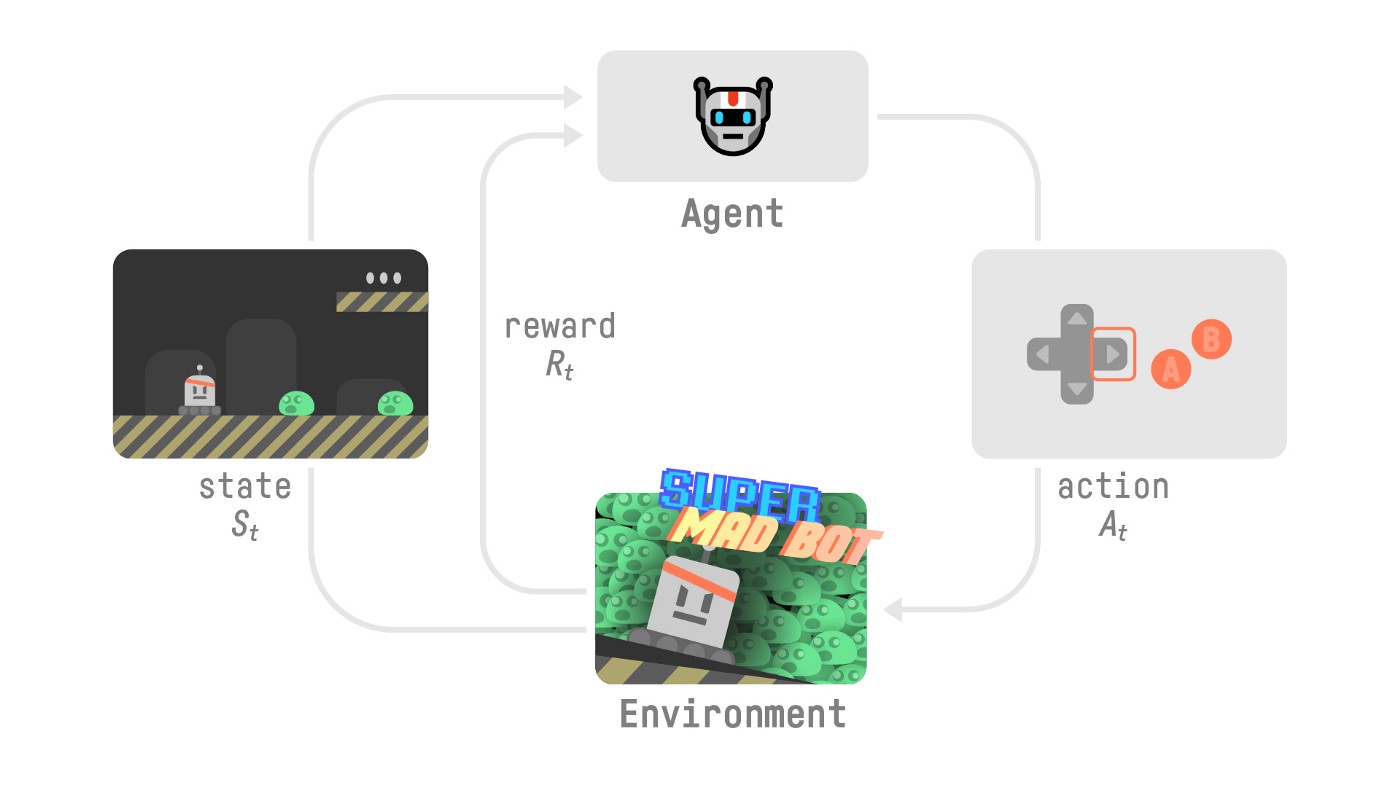
RL流程
- Our Agent receives state S0S_0S0 from the Environment — we receive the first frame of our game (Environment).
- Based on that state S0S_0S0, the Agent takes action A0A_0A0 — our Agent will move to the right.
- Environment goes to a new state S1S_1S1 — new frame.
- The environment gives some reward R1R_1R1 to the Agent — we’re not dead (Positive Reward +1).
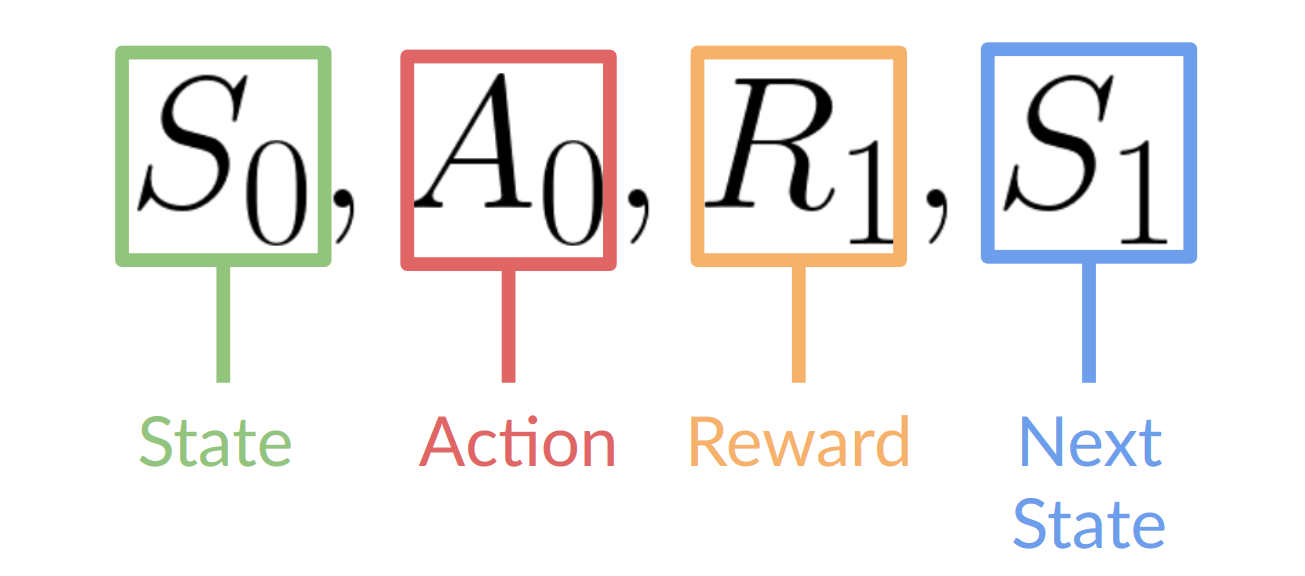
This RL loop outputs a sequence of state, action, reward and next state.
我们的代理从新环境收到状态S0S_0S0-我们收到游戏的第一帧(环境)。基于该状态S0S_0S0,如果代理采取行动A0A_0A0,我们的代理将向右移动。环境进入一个新的状态S1S_1s1-新的框架。环境给代理一些新的奖励R1R_1R1-我们没有死(正奖励+1)。这个RL循环输出状态、动作、奖励和下一个状态的序列。
The agent’s goal is to maximize its cumulative reward, called the expected return.
状态、行动、奖励、下一状态代理的目标是最大化其累积回报,称为预期回报。
The reward hypothesis: the central idea of Reinforcement Learning
奖励假说:强化学习的核心思想
⇒ Why is the goal of the agent to maximize the expected return?
⇒为什么代理商的目标是最大化预期收益?
Because RL is based on the reward hypothesis, which is that all goals can be described as the maximization of the expected return (expected cumulative reward).
因为RL基于预期回报假说,即所有目标都可以用预期回报最大(预期累计回报)来描述。
That’s why in Reinforcement Learning, to have the best behavior, we aim to learn to take actions that maximize the expected cumulative reward.
这就是为什么在强化学习中,我们希望拥有最好的行为,我们的目标是学习采取行动,使预期的累积回报最大化。
Markov Property
马尔科夫性质
In papers, you’ll see that the RL process is called the Markov Decision Process (MDP).
在论文中,你会看到RL过程被称为马尔可夫决策过程(MDP)。
We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it’s this: the Markov Property implies that our agent needs only the current state to decide what action to take and not the history of all the states and actions they took before.
我们将在下面的单元中再次讨论马尔可夫性质。但如果你今天需要记住一些关于它的事情,那就是:马尔可夫属性意味着我们的代理只需要当前状态来决定要采取什么行动,而不是他们之前采取的所有状态和行动的历史。
Observations/States Space
观察/状态空间
Observations/States are the information our agent gets from the environment. In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
观察/状态是我们的代理人从环境中获得的最新信息。在视频游戏的情况下,它可以是一帧(屏幕截图)。在交易代理的情况下,它可以是某一股票的价值等。
There is a differentiation to make between observation and state, however:
然而,观察和状态之间是有区别的:
- State s: is a complete description of the state of the world (there is no hidden information). In a fully observed environment.

In chess game, we receive a state from the environment since we have access to the whole check board information.
In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
Status s:是对世界状态的完整描述(没有隐藏的信息)。在一个充分观察的环境中。在国际象棋比赛中,我们从环境中接收到一个状态,因为我们可以获得整个棋盘的信息。在国际象棋游戏中,我们可以获得整个棋盘的信息,所以我们从环境中接收到一个状态。换句话说,环境得到了充分的观察。
- Observation o: is a partial description of the state. In a partially observed environment.

In Super Mario Bros, we only see a part of the level close to the player, so we receive an observation.
In Super Mario Bros, we only see a part of the level close to the player, so we receive an observation.
观察o:是对状态的部分描述。在一个部分观察的环境中。在超级马里奥兄弟中,我们只看到接近玩家的一部分关卡,所以我们接受了观察。在超级马里奥兄弟中,我们只看到接近球员的一部分关卡,所以我们收到了一个观察。
In Super Mario Bros, we are in a partially observed environment. We receive an observation since we only see a part of the level.
在超级马里奥兄弟中,我们处于一个部分被观察的环境中。我们收到了一个观测,因为我们只看到了水平的一部分。
In this course, we use the term “state” to denote both state and observation, but we will make the distinction in implementations.
在本课程中,我们使用术语“状态”来表示状态和观察,但我们将在实现中进行区分。
To recap:
简单地说:

OBS空间重述
Action Space
动作空间
The Action space is the set of all possible actions in an environment.
动作空间是环境中所有可能的动作的集合。
The actions can come from a discrete or continuous space:
这些行动可以来自一个离散的空间,也可以来自一个连续的空间:
- Discrete space: the number of possible actions is finite.
Again, in Super Mario Bros, we have only 5 possible actions: 4 directions and jumping
In Super Mario Bros, we have a finite set of actions since we have only 4 directions and jump.
离散空间:可能动作的数量是有限的。同样,在超级马里奥兄弟中,我们只有5个可能的动作:4个方向和跳跃。在超级马里奥兄弟中,我们有一个有限的动作集,因为我们只有4个方向和跳跃。
- Continuous space: the number of possible actions is infinite.

A Self Driving Car agent has an infinite number of possible actions since it can turn left 20°, 21,1°, 21,2°, honk, turn right 20°…
连续空间:可能动作的数量是无限的。自动驾驶汽车代理商有无限多的可能动作,因为它可以左转20°,21°,21°,21°,2°,按喇叭,右转20°…
To recap:
简单地说:

Taking this information into consideration is crucial because it will have importance when choosing the RL algorithm in the future.
动作空间重述将这些信息考虑在内是至关重要的,因为它在未来选择RL算法时将具有重要意义。
Rewards and the discounting
奖励和折扣
The reward is fundamental in RL because it’s the only feedback for the agent. Thanks to it, our agent knows if the action taken was good or not.
奖励在RL中是基本的,因为它不是对代理的唯一反馈。多亏了它,我们的代理才知道所采取的行动是好是坏。
The cumulative reward at each time step t can be written as:
每个时间点t的累计奖励可以写成:
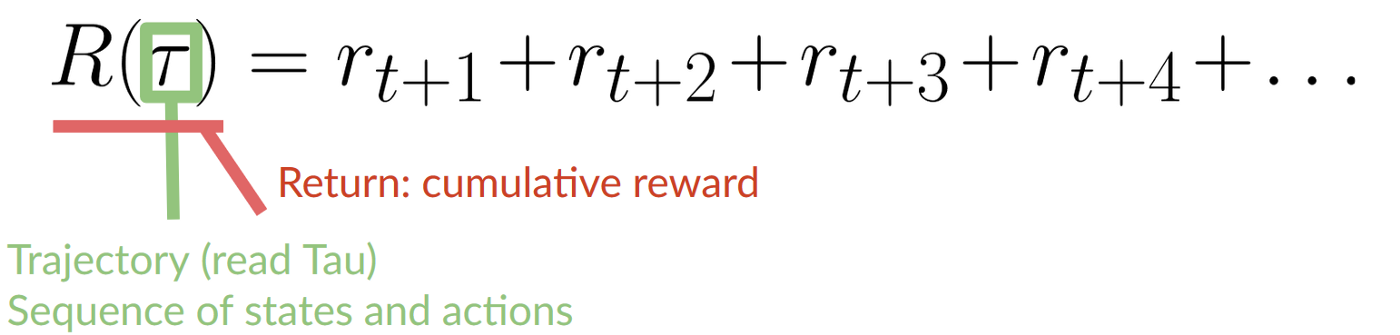
The cumulative reward equals to the sum of all rewards of the sequence.
奖赏累计奖赏等于序列的所有奖赏之和。
Which is equivalent to:
这相当于:
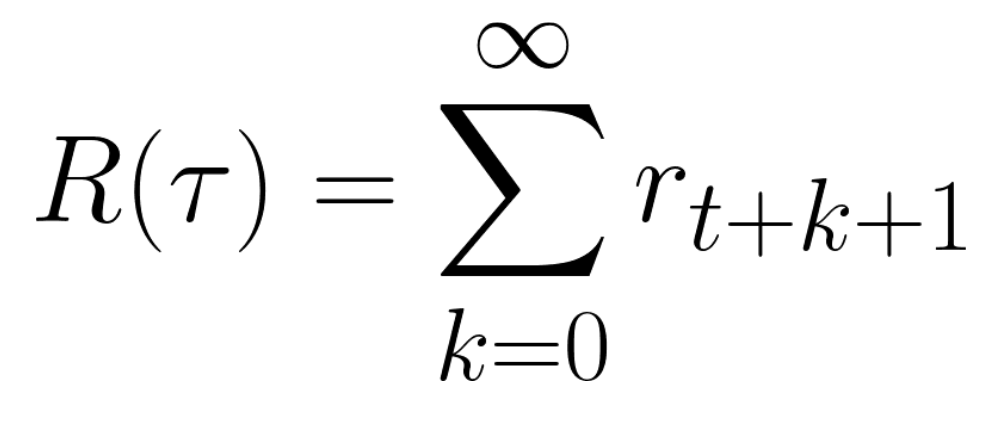
The cumulative reward = rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + …
累计奖励=RT+1(RT+k+1=RT+0+1=RT+1)+RT+2(RT+k+1=RT+1+1=RT+2)+…
However, in reality, we can’t just add them like that. The rewards that come sooner (at the beginning of the game) are more likely to happen since they are more predictable than the long-term future reward.
然而,在现实中,我们不能就这样简单地添加它们。更早到来的奖励(在比赛开始时)更有可能发生,因为它们比长期的未来奖励更可预测。
Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse’s goal is to eat the maximum amount of cheese before being eaten by the cat.
假设你的代理是一只每一步可以移动一块瓷砖的小老鼠,而你的对手是猫(它也会移动)。老鼠的目标是在被猫吃掉之前吃下最多的奶酪。

As we can see in the diagram, it’s more probable to eat the cheese near us than the cheese close to the cat (the closer we are to the cat, the more dangerous it is).
正如我们在图表中看到的那样,吃我们身边的奶酪比吃离猫近的奶酪更有可能得到回报(我们离猫越近,它就越危险)。
Consequently, the reward near the cat, even if it is bigger (more cheese), will be more discounted since we’re not really sure we’ll be able to eat it.
因此,猫咪附近的奖励,即使它更大(更多奶酪),也会有更大的折扣,因为我们真的不确定我们是否能吃到它。
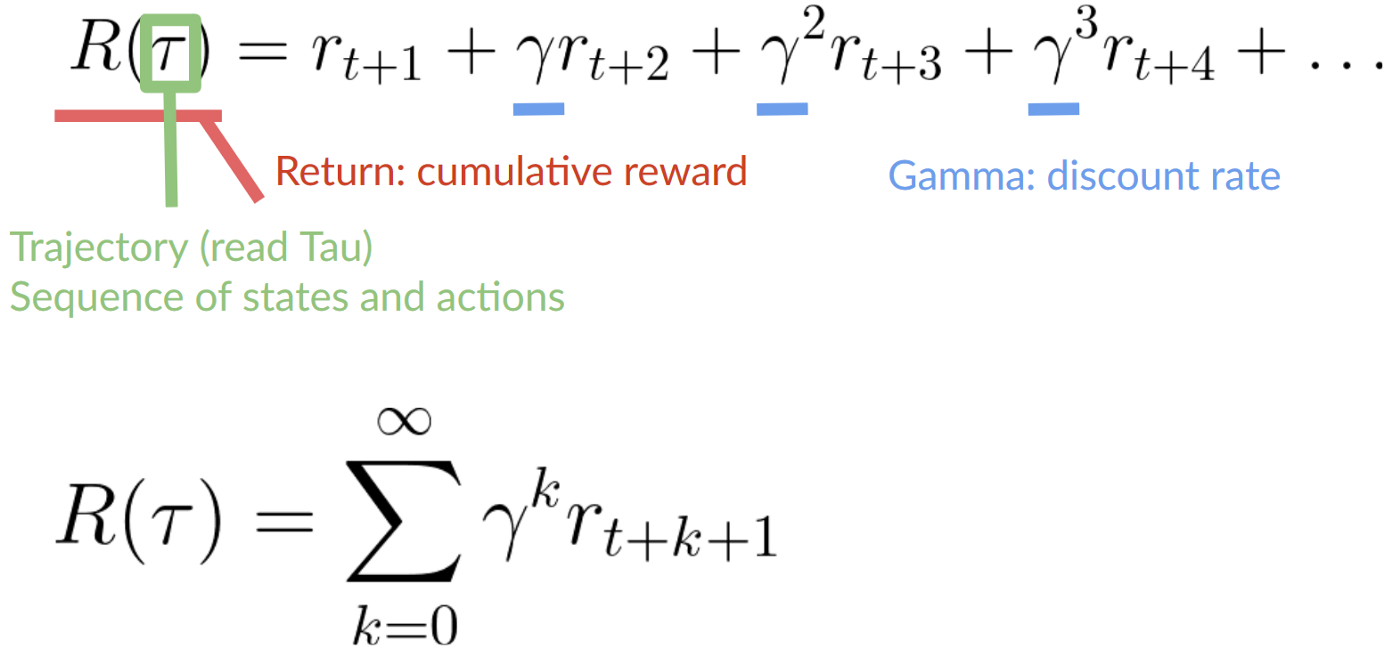
To discount the rewards, we proceed like this:
为了给奖励打折,我们是这样进行的:
- We define a discount rate called gamma. It must be between 0 and 1. Most of the time between 0.99 and 0.95.
- The larger the gamma, the smaller the discount. This means our agent cares more about the long-term reward.
- On the other hand, the smaller the gamma, the bigger the discount. This means our agent cares more about the short term reward (the nearest cheese).
2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, so the future reward is less and less likely to happen.
我们定义了一个称为伽马的贴现率。它必须在0到1之间。大多数时间在0.99到0.95之间。伽马越大,折扣越小。这意味着我们的代理商更关心长期回报。另一方面,伽马越小,折扣越大。这意味着我们的代理更关心短期奖励(最近的奶酪)2。然后,每个奖励将以伽马为时间步长的指数进行折扣。随着时间步长的增加,猫离我们越来越近,所以未来的奖励发生的可能性越来越小。
Our discounted expected cumulative reward is:
我们贴现的预期累积奖励是:
奖励